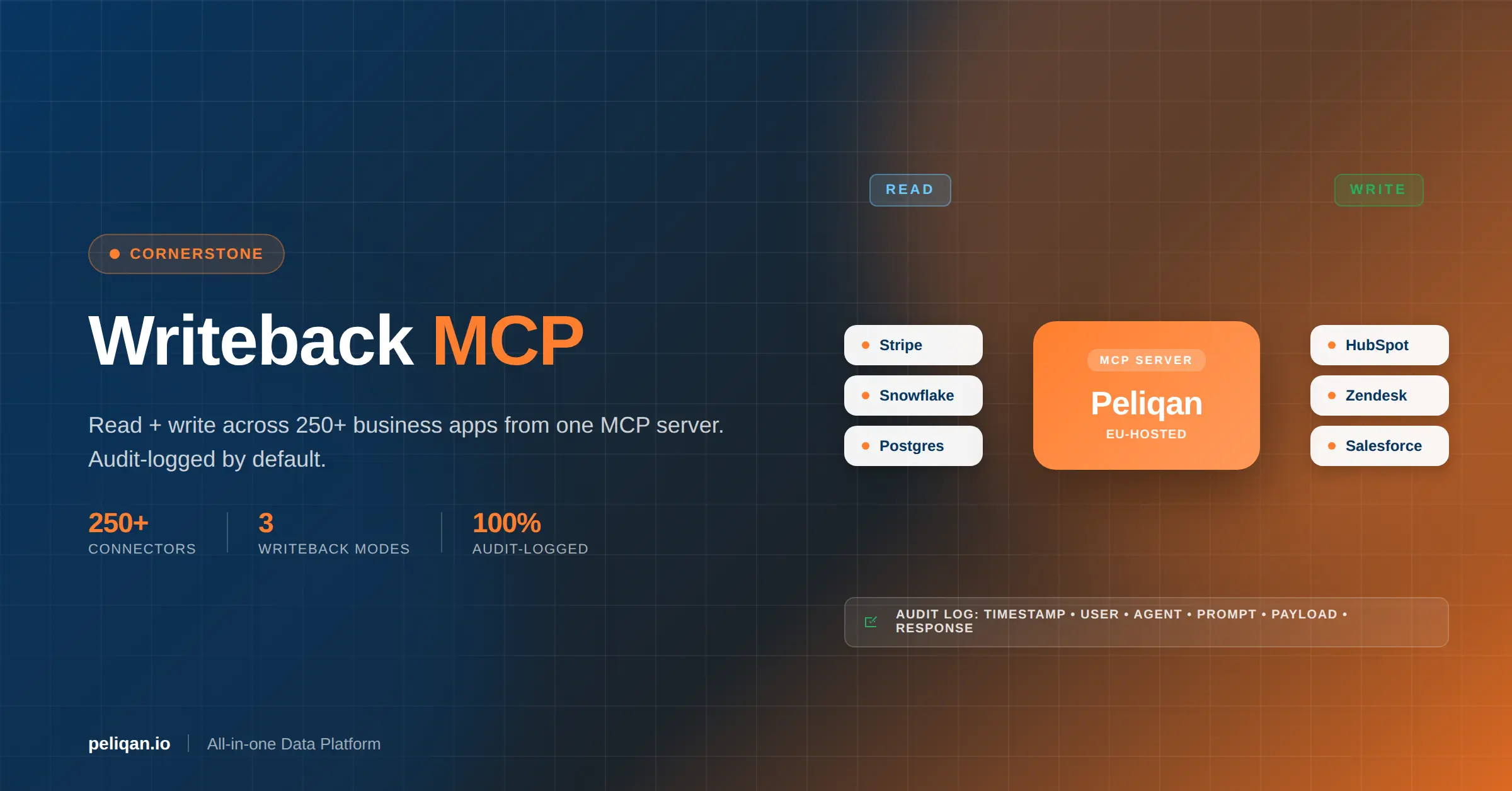





Most MCP servers stop at SELECT. That’s fine for analytics, but production AI agents need to act. Update a HubSpot lifecycle stage. Post a Slack alert. Create a Stripe invoice. Mark a Zendesk ticket resolved. That requires writeback, and as of June 2026 only a handful of MCP servers support it at all, and almost none with proper governance. This is the writeback MCP playbook.
The pain is concrete. Anthropic’s official Postgres MCP server (the reference implementation) is read-only. So is CData’s open-source MCP fleet. Snowflake’s managed MCP writes to Snowflake only. Zapier and Composio support writeback but meter every call as a billable task. Apideck reads and writes but flattens everything through a unified API.
So when a team builds an AI agent that needs to read from one system and write to another, the common pattern is the two-tool toggle: read via MCP, write via Zapier or a Make webhook. Two sources of truth, two trust boundaries, no audit chain. That breaks the moment a regulator (DORA, EU AI Act, GDPR) asks who wrote what, when, and on whose prompt.
This post defines the writeback MCP category, names the three modes, and shows where each MCP vendor lands. The cooperative architecture for AI agent writes in 2026 is a warehouse-first, audit-logged MCP server with per-table policy and reverse-ETL routing. That’s the category. Peliqan ships it across 250+ connectors.
What writeback means in the MCP context
Writeback in MCP means the AI agent can mutate state in a source system, not just read it. So the agent doesn’t just answer “what’s the lifecycle stage of this contact?” It writes the new lifecycle stage back to HubSpot when conditions are met.
Four kinds of writes the term covers
First, direct database mutations (INSERT, UPDATE, DELETE) against a Postgres, MySQL, or Snowflake table. Second, SaaS API writes (HubSpot contact update, Stripe invoice create, Zendesk ticket resolve). Third, audited writes where every mutation is logged with timestamp, user, agent, prompt, payload, and response. Fourth, queued writes where the agent stages the change and a human approves before commit.
How writeback differs from generic RPC tool calling
RPC tool calling sends one parameterized function call to one tool at a time. So an MCP server can wrap an RPC tool, but the writeback pattern adds three things RPC alone doesn’t deliver. First, a connection layer that holds the SaaS credentials so the AI client never sees the raw API key. Second, a policy layer that decides read versus write versus queue per role, per table, per field. Third, an audit log that captures the prompt, the user, and the payload for every mutation. The Claude MCP setup playbook covers the protocol-level details.
The 3 modes of MCP writeback
Mode 1: Direct write
The AI agent writes directly to the source system. The agent holds the API key. The mutation hits production with no intermediate layer. Fast and dangerous. Datadog Security Labs reported a SQL injection in Anthropic’s reference Postgres MCP server in 2025 that bypassed the read-only guardrail entirely. Even a server marketed as read-only could be made to write via a `COMMIT` injection that escaped the read-only transaction. So direct write is the easiest path to a write that nobody authorized.
Mode 2: Audited write
Every write is logged with user, agent, timestamp, SQL or payload, and response. This is the minimum for production. So a regulator (or an internal audit team) can answer “which user prompted which agent to write what to which system at what time” in one query. The audit log lives at the MCP server, not in the AI client. Otherwise a cleared Claude conversation removes the only trace. The EU AI Act and MCP Article 26 reference covers the six-month log retention obligation that high-risk deployers face from 2 August 2026.
Mode 3: Queued / human-in-the-loop write
The agent stages the change. A human reviews and approves before commit. Best for financial transactions, mass updates, anything regulated. So a Stripe invoice over €10,000, a Salesforce opportunity stage change, a HubSpot bulk lifecycle update gets a human signoff in Slack, Teams, or email before the write fires. n8n, Workato, and LangGraph all implement this pattern at the workflow layer. The cleanest MCP-native pattern is per-table or per-action queue policy enforced at the server.
When to use each mode
The 7 standing writeback workflows every team wants
If you ship an AI agent in 2026, these seven writebacks come up week one. None of them works in a pure read-only MCP. So a writeback-capable MCP server is the dependency.
The 3 failure modes of read-only MCPs
This is the defensible IP. Three failure modes recur across every read-only MCP deployment we audit. Each one is structural, not a vendor bug.
Failure mode 1: the two-tool toggle
The team reads via an MCP server and writes via a separate Zapier or Make webhook. So now there are two trust boundaries, two audit gaps, and two API keys to rotate. The agent’s prompt-to-write chain is fragmented across two systems that don’t share an audit log. When the regulator asks “which user prompted which agent to write what,” the answer requires manually joining two different observability stacks. The GitHub issue anthropics/claude-code#30142 documents the operational pain: users maintain 80+ permission entries because there’s no standard read-only-vs-read-write annotation in MCP itself.
Failure mode 2: raw API keys in agent config
DIY writeback usually means pasting production API keys into Claude, Cursor, or Codeium settings. So the agent’s config file holds production credentials. Anyone with shell access to the developer’s laptop can read them. Anthropic’s reference Postgres MCP server made this concrete: the connection string was passed as a command-line argument, which meant anyone who could run `ps` on the host could read the password. Furthermore, the AI client itself can leak the credential through error messages or logs. The fix is structural. Credentials live in the MCP server, not in the AI client. The Postgres MCP setup guide covers the credential-isolation pattern.
Failure mode 3: no audit trail
The agent writes. Nobody can trace which user, which prompt, which timestamp, which agent caused which mutation. This breaks DORA Article 12 of the RTS on ICT risk management (logging procedures), EU AI Act Article 26(6) (six-month log retention for high-risk deployers), and GDPR Article 30 (records of processing). So a write that lands in production with no audit entry is a regulatory miss the moment a supervisor asks for the chain of custody.
For the GDPR layer specifically, see our GDPR-compliant MCP servers reference.
For the DORA layer, see our DORA + MCP financial services playbook.
The 8-vendor writeback comparison matrix
Verified status as of June 2026. Read-only by design, read-only by default, action-based, source-bound, and fully audited writeback are the five lanes. Most vendors sit in one of the first three. Only one sits in the fifth.
For a deeper architectural breakdown of the third-party options, see our 8-way MCP architecture comparison.
Why audited writeback matters more in 2026
Three regulations converged on logging in 2025-2026. So audited writeback isn’t a nice-to-have for EU buyers anymore. It’s the procurement minimum.
DORA Article 12 logging
Commission Delegated Regulation (EU) 2024/1774 (the RTS on ICT risk management framework) Article 12 requires every financial entity to develop, document, and implement logging procedures, protocols and tools covering ICT third-party service mutations. DORA has applied since 17 January 2025. So every MCP write to a regulated data system in a bank, insurer, or payment institution must be logged with full context. The DORA Article 28 ICT third-party register obligation extends to the MCP vendor itself.
EU AI Act Article 26(6)
Deployers of high-risk AI systems must “keep the logs automatically generated by that high-risk AI system… for a period appropriate to the intended purpose… of at least six months.” High-risk obligations apply from 2 August 2026 under the current text. A provisional Digital Omnibus agreement from May 2026 could push this to December 2027, but it isn’t enacted yet. So plan to the August 2026 date. Annex III includes credit scoring, insurance pricing, and recruitment ranking. Every MCP write touching these workflows lands in the six-month retention window.
GDPR Article 30 records of processing
Every processor and controller must maintain records of processing activities. Automated AI writes to personal data records fall inside Article 30 by default. So the audit log of an MCP writeback to a HubSpot contact, a Salesforce lead, or a Zendesk requester is the evidence for the Article 30 record. Furthermore, ISO 27001:2022 Annex A.5.15 (access control) and A.8.15 (logging) map directly onto the per-role permissions and audit log pattern.
How Peliqan’s writeback works
Peliqan’s writeback is the audited-by-default pattern. Four layers, each one solving a specific failure mode from the section above.
Connection layer: scoped per-user API key
AI clients authenticate to Peliqan via an API key scoped per user or per agent. So the live SaaS credentials (HubSpot OAuth token, Stripe restricted key, Zendesk API token) live inside Peliqan’s encrypted credential store. The AI client never sees them. Failure mode 2 (raw API keys in agent config) disappears because there are no raw API keys to leak.
Policy layer: read, write, or queue per table
Permissions are read-only by default. The admin enables INSERT, UPDATE, DELETE per role, per schema, per table, or per field. So a customer success agent can update Zendesk ticket status but cannot update Stripe charges. A revenue ops agent can update HubSpot lifecycle stage but cannot delete contacts. The permissions documentation covers the policy primitives. Column-level masking handles PII at the same layer.
Audit log: prompt, user, agent, payload, response
Every write produces an audit log entry. Timestamp. Authenticated user. AI agent identifier. Originating prompt. SQL statement or API payload. Source-system response. So when DORA, EU AI Act, or GDPR audit time arrives, the chain of custody is one query, not a forensics project. Furthermore, the audit log is retained inside Peliqan’s EU-hosted Postgres (AWS Frankfurt), so it satisfies GDPR Article 48 jurisdiction by default.
Reverse ETL: bulk writebacks routed through the connector layer
Bulk writebacks (mass-update enrichment, batch invoice generation, multi-thousand-row reconciliation) route through Peliqan’s reverse ETL rather than through synchronous MCP calls. So the connector layer handles rate-limit budgeting (Zendesk’s 30 updates per 10 minutes per ticket, Salesforce’s API budget, HubSpot’s daily limits) instead of letting the AI agent saturate the SaaS API. The MCP server queues the bulk request, reverse ETL drains it under rate-limit guardrails, and the audit log captures every individual mutation.
5 sub-segments that need writeback most
For the RevOps and DTC patterns specifically, see our HubSpot MCP playbook.
For the customer-success pattern, see our Zendesk MCP churn-risk playbook.
Real-world example: CIC Hospitality
CIC Hospitality unified 50+ data sources across its multi-property portfolio into Peliqan’s EU-hosted Postgres + Trino warehouse. The team automated board reporting and saved more than 40 hours per month. The same architecture handles writebacks across the property stack. PMS updates, channel manager rate changes, F&B adjustments. Every write is audit-logged. Every credential stays in Peliqan, never in the AI client. Read the full CIC Hospitality case study.
Pricing reality for writeback MCP
Writeback MCP pricing varies wildly across the eight vendors above. So the comparison isn’t “which vendor is cheapest.” It’s “which pricing model fits a writeback workload.”
So for any team running more than a few hundred writebacks per month, the flat-rate model dominates economically. The MCP server pricing question is covered in depth in our MCP server pricing 2026 guide.
The bottom line on writeback MCP
The MCP protocol doesn’t enforce read-only or read-write. So every MCP server gets to choose. Most reference servers chose read-only as a safety default. That was the right call in 2024. In 2026, AI agents in production need to act, not just inform. So the writeback question moved from optional to required for any team building agents past the demo stage.
However, writeback without governance is worse than read-only. Direct writes against production with no audit log is the regulatory failure mode that DORA, EU AI Act, and GDPR converged on. So the cooperative architecture for 2026 is read-only by default, scoped writeback per role per table, every write logged with full prompt-to-payload context, and bulk writes routed through reverse ETL.
Peliqan ships this pattern across 250+ connectors as a first-class feature. EU-hosted in Belgium, SOC 2 Type II, ISO 27001 certified, GDPR-native. The credentials stay in Peliqan, the audit log captures every write, and the policy layer handles per-role enablement. So the writeback MCP category has a default answer for the EU buyer who hit the read-only wall and didn’t want to paste a production API key into Claude.
This post is informational. Vendor pricing, product features, and AI Act timelines reflect publicly available information as of June 2026 and may change. Verify current details with each vendor before any procurement decision.