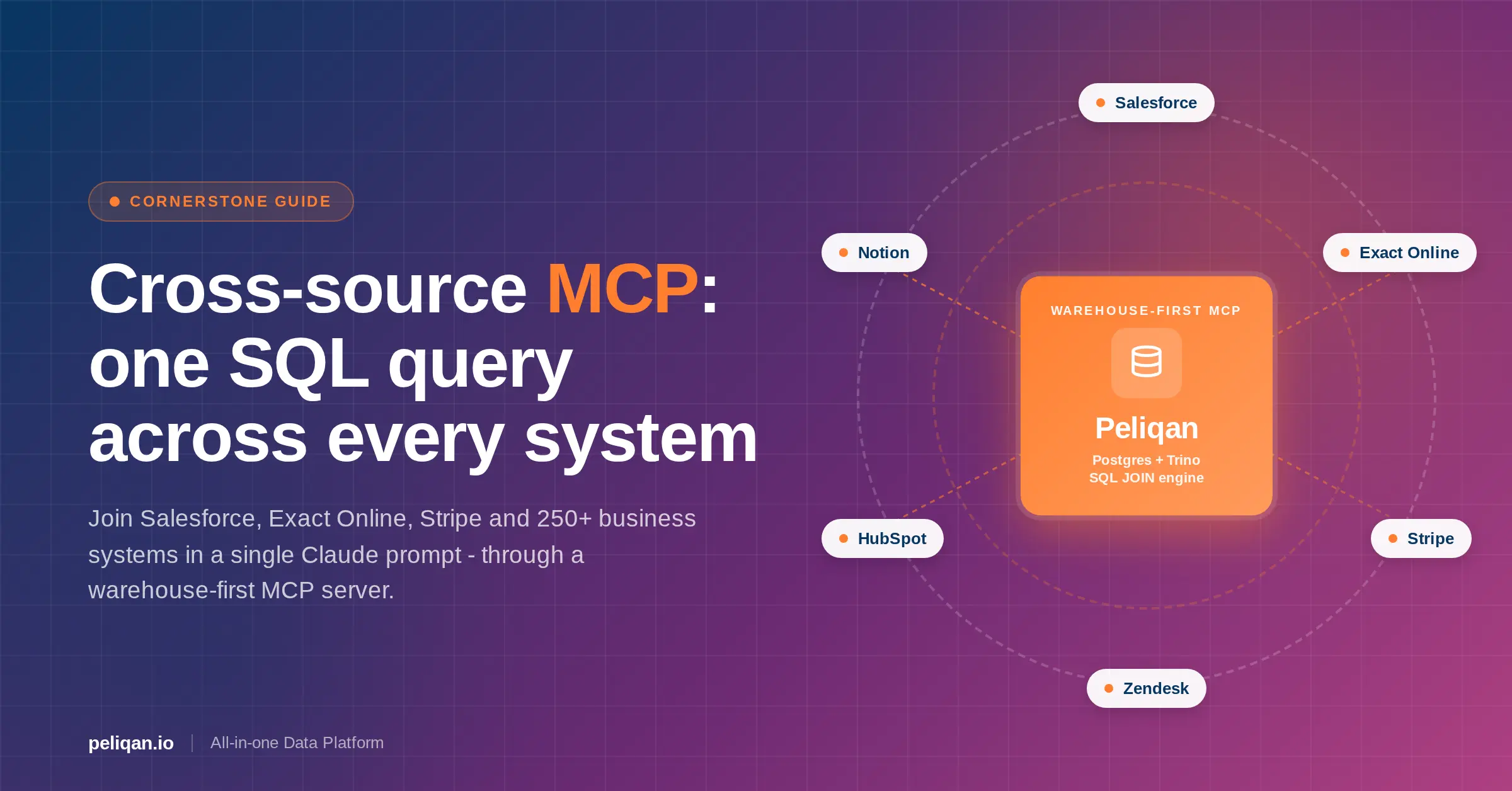





Cross-source MCP is the architectural pattern that lets an AI agent answer questions that span two, three, or seven business systems in a single SQL query – not by orchestrating calls to seven different MCP servers, but by joining their data inside one governed warehouse. It’s the difference between “Claude can read Salesforce” and “Claude can tell you which top-100 customers have overdue Exact Online invoices and open Zendesk tickets.” Most MCP servers shipped in 2025 and 2026 cannot do the second one. This post explains why, and how to build the architecture that can.
The Model Context Protocol crossed the chasm in the first half of 2026. Salesforce made hosted MCP servers generally available in April. Workato has been shipping “MCP Monday” weekly since October 2025, now past 38 pre-built servers. Apideck launched 229 tools auto-generated from OpenAPI on Product Hunt in May. Microsoft, SAP, ServiceNow, Atlassian, GitHub, Box, HubSpot – every enterprise vendor of consequence has shipped an MCP server or announced one for 2026.
That part is solved. What isn’t solved is the question every CFO, head of RevOps, and CTO eventually asks: “If I have an MCP server for Salesforce, another for Exact Online, and another for Stripe, can my AI agent answer a question that spans all three in one prompt?”
The honest answer for most stacks shipping today is no. Not natively. Not in one SQL query. Not without an orchestration layer that the per-vendor MCP servers don’t include. This is the architectural gap that cross-source MCP exists to close, and it’s the boring infrastructure decision that quietly compounds for the next five years of agentic work.
What BotsCrew’s enterprise framing actually proves
In a May 2026 piece on MCP for enterprise, the consultancy BotsCrew describes the three patterns of MCP rollouts that have generated meaningful ROI. The first – and the one they put first – is cross-system reasoning. Their example: “A sales leader asks Claude, ‘Which deals slipped this quarter, why, and what does Finance think the revenue impact is?’ Claude pulls from Salesforce, cross-references the company’s forecasting model, and references the latest call transcripts in your knowledge base – all through MCP servers, in a single conversation.”
The conclusion of that section is the line every architect should pin to the wall: “The value comes from the systems being connected, not from the model alone.” That’s true. It’s also a description of a problem, not a solution. Connecting three vendor-published MCP servers to one Claude session is trivially easy in 2026. Getting them to answer a single SQL question that spans Salesforce opportunities, the forecasting model, and the call transcripts in one query – with consistent schemas, joinable keys, and an audit log that survives a SOC 2 review – is not trivial. It’s the open architectural problem of the year.
The four MCP architectural patterns and what each can actually do
- Per-API MCP wrappers (Salesforce’s hosted MCP, Stripe Agent Toolkit, Notion MCP, Xero JAX, Microsoft BC MCP): excellent inside their vendor. No shared schema across servers, no cross-source SQL.
- Workflow MCPs (Pipedream, Zapier MCP, n8n nodes): event-driven and action-shaped. No analytical layer, no JOINs, task-quota economics.
- Unified-API MCPs (Apideck, Merge, Finch): one schema across many providers. Read-mostly, flat, no cross-API JOINs at the SQL layer.
- Warehouse-first MCPs (Peliqan, K2view, the mcp-trino pattern): per-connector depth landed into a federated warehouse. Real SQL with JOINs, window functions, and CTEs across every connected source.
Why three of the four patterns cannot join across sources
The four patterns are not equally good at the same job. Choosing between them is mostly an architectural decision about where the join happens – inside a vendor, inside a workflow runtime, inside a unified schema, or inside a warehouse. Each location has a structural ceiling.
Pattern 1: per-API MCP wrappers
The fastest-growing pattern in 2026 is one MCP server per business system, each shipped by the vendor of that system. Salesforce’s hosted MCP exposes accounts, opportunities, and cases. Stripe’s Agent Toolkit exposes charges, customers, and disputes. Notion’s MCP exposes pages and databases. Microsoft’s Business Central MCP went GA in February. Each of these is excellent inside its own vendor surface.
The structural ceiling is that each MCP server is its own protocol surface. There’s no shared schema, no shared identifiers, no shared query language across servers. When Claude is connected to three of them in one session, it can call tools on all three in the same turn – but it can’t write a SQL JOIN between them. The “join” happens in the agent loop, which means each cross-source question becomes a sequence of round-trips, prompt-engineered correlation logic, and per-call token cost. It works for “find this customer’s invoices and tickets and summarise” – it does not work for “rank all 5,000 customers by combined risk score across these three tables.”
Pattern 2: workflow MCPs
Pipedream, Zapier MCP, and n8n’s MCP nodes wrap thousands of APIs into action-shaped tools. They’re built for event-driven automation – “when a Stripe payment fails, post to Slack and update Salesforce.” They’re terrific at that job. The structural ceiling is that they’re not analytical layers. Each call is a workflow step. There’s no cached warehouse, no schema layer the agent can introspect at SQL level, and the economics are quota-based: every tool call burns a task on the bill.
For cross-source analytical questions, this pattern collapses for two reasons. First, latency: an analytical question that touches 20,000 rows across three systems is 20,000 tool calls, not one query. Second, governance: the action logs are sufficient to defend a single workflow firing in a Big-4 audit, but they don’t reconstruct a Claude prompt that read 200 records from Salesforce and 300 from Exact Online to compute a single answer.
Pattern 3: unified-API MCPs
Apideck, Merge, and Finch take a different approach: normalise multiple APIs behind a single unified schema. Apideck’s 229-tool MCP server, auto-generated from their OpenAPI spec, is one of the most technically elegant examples of this pattern shipped to date. It’s purpose-built for embedded SaaS – the builder who wants their customers to plug in any accounting system and not care which one.
For that use case it wins cleanly. The structural ceiling for cross-source analytical SQL is different: unified APIs are read-mostly and flatten to the lowest common denominator across providers. Apideck’s “Unified Accounting” exposes invoices and journal entries that look the same whether the underlying system is Exact Online, NetSuite, or QuickBooks. That’s the feature, and it’s the limitation. You can’t write a SQL JOIN across two unified APIs (accounting + CRM) because each unified API is its own MCP surface. And the per-connector depth – Exact Online’s 12 divisions, AFAS’s Get-Connectors, NetSuite’s subsidiary structure – is intentionally hidden by the unification, which is exactly what the embedded SaaS builder wants but exactly what the internal CFO doesn’t.
Pattern 4: warehouse-first MCPs
The fourth pattern lands every connector’s data into a single warehouse, then exposes one MCP server that speaks SQL against that warehouse. The MCP server doesn’t proxy the upstream API at query time – it queries the cached, schema-aware, governance-applied warehouse copy. That’s how a single SQL statement can join Salesforce accounts to Exact Online invoices to Stripe payments to Zendesk tickets in one round-trip, with one audit log, one permissions surface, and one consistent semantic layer the agent can introspect.
This is the pattern Peliqan ships, and the pattern that mcp-trino implementations approximate at the open-source layer. K2view’s data-product approach lands in the same architectural slot from a different starting point (operational data products instead of an analytical warehouse). The shared feature is that the join happens in a real SQL engine, not in the agent loop, not in a workflow runtime, and not behind a flat unified schema.
Ten real cross-source SQL examples Claude can actually run
To make this tangible, here are ten cross-source questions a CFO, RevOps lead, or head of customer success could ask in plain English, alongside the SQL Peliqan executes against its Postgres + Trino warehouse to answer them. The point isn’t the SQL syntax – it’s that this is a single statement, not seven tool calls, not a workflow, not a unified-API read.
1. Top-100 customers at combined risk
Question: “Which top-100 customers by ARR have at least one overdue Stripe payment in the last 30 days and at least one open Zendesk Sev-1 ticket?”
SELECT sf.account_name, sf.arr, COUNT(DISTINCT z.ticket_id) AS open_sev1, SUM(s.amount_due) AS overdue_amount FROM salesforce.accounts sf JOIN stripe.invoices s ON s.customer_id = sf.stripe_customer_id JOIN zendesk.tickets z ON z.organization_id = sf.zendesk_org_id WHERE s.status = 'past_due' AND s.due_date >= NOW() - INTERVAL '30 days' AND z.priority = 'urgent' AND z.status = 'open' GROUP BY sf.account_name, sf.arr ORDER BY sf.arr DESC LIMIT 100;
This is the prompt that fails on every per-API MCP stack because Salesforce, Stripe, and Zendesk each have their own MCP server with their own schema and no shared customer identifier the agent can rely on without writing correlation code. In a warehouse, the join keys are reconciled at sync time once and live as a foreign key forever.
2. Exact Online overdue invoices crossed with Salesforce account tier
Question: “Show me Exact Online MCP invoices past due more than 30 days, grouped by Salesforce account tier, with the Billit Peppol delivery status alongside.”
SELECT sf.tier, COUNT(*) AS overdue_count, SUM(e.amount) AS overdue_total,
SUM(CASE WHEN b.peppol_status = 'delivered' THEN 1 ELSE 0 END) AS peppol_delivered
FROM exact_online.invoices e
JOIN salesforce.accounts sf ON sf.exact_customer_id = e.customer_id
LEFT JOIN billit.peppol_log b ON b.invoice_number = e.invoice_number
WHERE e.due_date < NOW() - INTERVAL '30 days' AND e.status = 'open'
GROUP BY sf.tier ORDER BY overdue_total DESC;
This is the Belgian CFO’s standing weekly question. The Peppol e-invoicing mandate live in BE since January 2026 makes the third join non-optional – the CFO needs to know whether the invoice was even electronically delivered before chasing payment. That third join is exactly the kind of vertical depth a unified-API MCP flattens away.
3. Pipeline forecast cleaning across three sources of truth
Question: “Compare Pipedrive’s forecast for this quarter against Stripe’s already-realised MRR and Exact Online’s closed-won revenue. Flag any deal Pipedrive has at > 75% probability where Stripe shows no payment intent.”
WITH pd AS (
SELECT deal_id, account_id, expected_close, value, probability
FROM pipedrive.deals WHERE expected_close BETWEEN DATE_TRUNC('quarter', NOW())
AND DATE_TRUNC('quarter', NOW()) + INTERVAL '3 months'
), sp AS (
SELECT customer_id, SUM(amount) AS realised FROM stripe.payment_intents
WHERE status = 'succeeded' AND created >= DATE_TRUNC('quarter', NOW()) GROUP BY 1
)
SELECT pd.deal_id, pd.value, pd.probability, COALESCE(sp.realised, 0) AS stripe_realised
FROM pd LEFT JOIN sp ON sp.customer_id = pd.account_id
WHERE pd.probability > 75 AND COALESCE(sp.realised, 0) = 0;
Three CTEs, a left join, a window function over a quarter. Standard analytical SQL. Impossible to express as a single tool call against three separate vendor MCP servers.
4. MEWS pickup curve crossed with Stripe revenue per property
Question: “For each property in the group, show 30-day rolling RevPAR from MEWS reservations against Stripe payments cleared, surfaced as a daily trend.”
This is a question the MEWS + Claude blog walks through in depth for multi-property hotel groups. The reservation system and the payments system rarely line up day-of without a join layer, because cancellations, chargebacks, and currency conversions create real revenue drift the GM needs to see by tomorrow morning, not on the month-end close.
5. Notion roadmap crossed with Stripe MRR by feature
Question: “Which features on the Notion roadmap database are tagged ‘shipped this quarter’ and which Stripe products have seen MRR growth since they shipped?”
SELECT n.feature, n.shipped_date,
(SELECT SUM(amount) FROM stripe.subscription_items si
WHERE si.product_id = n.stripe_product_id
AND si.created > n.shipped_date) AS mrr_since_ship
FROM notion.roadmap n
WHERE n.status = 'Shipped this quarter'
ORDER BY mrr_since_ship DESC NULLS LAST;
The cross-source insight – “did this feature actually move money?” – is invisible to either Notion’s MCP or Stripe’s Agent Toolkit alone. It lives in the JOIN.
6. HubSpot MQL to Salesforce SQL to Stripe closed-won funnel cohort
Question: “Take MQLs created in HubSpot in Q1, find the matching Salesforce opportunities they became, and show closed-won Stripe revenue by acquisition channel.”
The HubSpot MCP setup handles the source-of-truth question between HubSpot and Salesforce that every RevOps team eventually has. The Stripe layer adds the only metric that ultimately matters to the board, and the channel cohort makes the answer actionable for the marketing team.
7. AFAS HR crossed with Teamleader projects and Stripe revenue
Question: “Show me the people-project-revenue triangle: which consultants in AFAS HR are billing against which Teamleader projects, and what’s the realised Stripe revenue per consultant this quarter?”
This is the standing question for Benelux services firms with mixed HR, project, and billing stacks. The AFAS AI surface exposes the HR Get-Connectors with their native depth – employee, contract, hours – which is the kind of vertical fidelity flattened away by unified APIs. The Teamleader MCP server brings the project and CRM layer into the same warehouse, so the JOIN is a single statement instead of a three-system reconciliation script.
8. Yuki invoices crossed with bank reconciliation
Question: “For each Yuki invoice open more than 14 days, show the bank reconciliation status and the customer’s last three Stripe payment intents.”
The BE and NL SMB cash cycle runs through this query weekly. Yuki holds the invoice, the bank reconciliation feed holds the payment, Stripe holds the historical signal of whether this customer pays on time. Joining all three is the difference between “send another reminder” and “this account needs a call.”
9. NetSuite multi-subsidiary crossed with Salesforce regional pipeline
Question: “Roll up NetSuite revenue by subsidiary and currency, then show Salesforce pipeline coverage ratio by region for the next two quarters.”
PE-backed multi-entity groups live in this query. Oracle shipped an official NetSuite MCP in Q1 2026, but it’s a single-subsidiary view by default; rolling up across subsidiaries with currency translation is exactly the kind of query that wants to happen in a warehouse where the FX rates are materialised next to the revenue rows. The same multi-entity pattern applies to Odoo MCP rollouts for partner consultancies running 50+ client environments at once.
10. Xero practice-wide crossed with Stripe for SaaS-client accounting
Question: “Across every client in our Xero practice, which ones are also Stripe customers of our SaaS business, and what’s the gap between their last invoice paid and their last Stripe charge?”
UK accountancy partners with SaaS sidecars run this query. Xero practice-wide reporting is good inside Xero; Stripe payments analytics are good inside Stripe. The combined view – “are our biggest accounting clients also paying us for our SaaS?” – lives in the JOIN nobody else can write.
What changes when the join lives in a warehouse
The architectural argument for warehouse-first MCP is not about preference. It’s about which kinds of question are answerable in one query versus seven. A few specifics that compound over time.
The four things a warehouse beneath the MCP server unlocks
The vendor-native MCPs that are great and the boundary they hit
This is where fair-framing matters. Stripe’s Agent Toolkit is excellent for in-Stripe agent workflows. Salesforce’s Agentforce 3 MCP support brings real tool-calling discipline to in-CRM agents. Notion’s MCP is the best way to let Claude reason about Notion content. Microsoft’s Business Central MCP, GA’d in February 2026 with the 2025 Wave 2 release, is the right answer for in-BC agent work. Xero’s JAX is the right answer for in-Xero accounting agents.
Every one of these is great inside its vendor surface. None of them is designed to leave the vendor surface. That’s not a flaw; it’s the design point. The cross-source question is a different job, and asking a vendor MCP to do it is asking it to do something it was never scoped for. The warehouse-first MCP is the architectural complement, not the replacement.
How the four patterns compare side by side
The architecture underneath Peliqan’s cross-source MCP server
To make the warehouse-first pattern concrete, here’s what Peliqan ships under the hood. The MCP server is the thin top layer; the analytical Postgres surface beneath it is where the cross-source magic happens.
Four layers from connector to Claude prompt
The Trino part deserves a callout because it’s the piece most teams don’t think about until they need it. Trino is the open-source federated SQL query engine that lets one query span MySQL, Postgres, S3, MongoDB, Kafka, and dozens of other sources without copying data first. For an MCP architecture, that means the agent can run a single SQL statement that joins a materialised Exact Online table in Postgres to a live Snowflake view of revenue, and the warehouse engine handles the federation. The agent doesn’t have to know – it just sees one schema.
Why the warehouse beneath matters more than the MCP server itself
This is the architectural decision that quietly compounds. An MCP server is a thin protocol layer. The hard work – schema reconciliation across 250+ sources, per-connector depth preservation, audit logging at the prompt-to-SQL level, federated query optimisation, reverse ETL writeback with attribution – happens beneath it. Vendors that built the warehouse first and exposed an MCP layer on top inherit all of that for free. Vendors that started with the MCP server and tried to bolt analytics on later end up rebuilding a warehouse, badly, inside the MCP layer.
The Peliqan platform page covers the warehouse architecture in depth. The SQL on anything help doc walks through the federated query patterns. The point in the context of this post is that the MCP server’s value is bounded by what’s underneath it. A warehouse is the only thing under it that survives the second year of agentic workloads.
Choosing the right pattern: a decision framework
When to pick which MCP pattern
- If the agent never has to leave one vendor: use the vendor’s per-API MCP. Stripe Agent Toolkit for in-Stripe work, Salesforce Agentforce MCP for in-Salesforce work, Notion MCP for in-Notion work, Microsoft BC MCP for in-BC work. Don’t over-architect.
- If the job is event-driven automation: use a workflow MCP. “When a Stripe payment fails, update Salesforce and post to Slack” is exactly what Pipedream and Zapier are designed for.
- If you’re building an embedded integration product: a unified-API MCP like Apideck is the right architectural fit. End-customers shouldn’t feel the difference between Exact and NetSuite.
- If the job is internal cross-source analytics, finance, or RevOps: warehouse-first. The questions in this post all assume cross-source SQL and audit-logged writeback – that’s the warehouse pattern’s home turf.
- If you need all four jobs: they compose. A warehouse-first MCP for analytics plus a vendor MCP for in-vendor actions plus a workflow MCP for events is a valid architecture. The pieces don’t compete; they layer.
Cross-source MCP and the compliance question
The audit-log argument lives in the background of every architectural choice until something goes wrong. With the EU AI Act’s Article 26 obligations enforced from August 2, 2026, and DORA already live for financial services since January 2025, the question stops being academic. A high-risk AI deployer has to produce automatically-generated logs of every action the AI system took, with human-oversight provenance, on demand.
A per-API MCP stack has one audit log per vendor, none of which share a customer identifier or a prompt context. A workflow MCP stack has per-run logs that don’t reconstruct the analytical question that triggered them. A unified-API MCP has one log per unified-API surface, which is better, but still doesn’t reconstruct the SQL the agent didn’t actually run.
A warehouse-first MCP has one log of every prompt-to-SQL translation, every row read, every reverse-ETL writeback, with the AI session ID attached. That’s the artefact a SOC 2 auditor wants. It’s also the artefact the Article 26 compliance officer wants. Peliqan ships SOC 2 Type II, ISO 27001 in progress, and EU-hosted infrastructure as a baseline, which removes the CLOUD Act risk that follows US-hosted MCPs into European data residency conversations.
Real-world example: CIC Hospitality
CIC Hospitality consolidated 50+ data sources across PMS, payments, accounting, and operational systems into a single Peliqan warehouse, then exposed it through one MCP server for board-grade reporting. The team reports more than 40 hours per month saved on report assembly that used to require multi-system manual joins. Read the full CIC Hospitality case study.
How to get started with a cross-source MCP setup
The set-up has three concrete steps, and most teams complete the first two in an afternoon.
First, connect your top three data sources to Peliqan. For a typical RevOps stack, that’s the CRM (Salesforce or HubSpot), the payments system (Stripe), and one ERP or accounting source (Exact Online, Yuki, AFAS, NetSuite, Xero, or Business Central). The AFAS MCP server is a useful reference for what a per-connector landing looks like in practice. The connector layer materialises the tables into the warehouse on the schedule you pick.
Second, install the MCP server: pip install mcp-server-peliqan, add your API token, point Claude or Cursor or n8n at it. The Peliqan MCP server help doc walks through the configuration, including the Claude MCP setup specifics if Claude is your client.
Third, ask the cross-source question that’s been on your list. The first one is usually one of the ten above. The second is whatever your CFO has been asking the data team for over Slack on Friday afternoons. From there, the queries write themselves – and the warehouse beneath them is the boring architectural decision that quietly compounds for the next five years.
The bottom line on cross-source MCP
The MCP ecosystem in 2026 is no longer a question of whether your business systems will have AI access. They will. Salesforce, Microsoft, Stripe, Notion, SAP, ServiceNow, and 38+ Workato-published MCP servers have already settled that question. The architectural decision that’s still in play is where the cross-source join happens.
If the join lives in the agent loop, every cross-source question becomes a sequence of round-trips, prompt-engineered correlation logic, and per-call audit gaps. If it lives in a workflow runtime, it becomes a quota-bound batch job that doesn’t compose with analytical work. If it lives in a unified-API surface, it gets flattened to the lowest common denominator across providers. If it lives in a warehouse, it becomes a SQL query the CFO can read – and the audit log the compliance team can defend.
For every internal-facing agent that has to span more than one business system, the warehouse beneath the MCP server is the architectural decision that survives the second year. It’s the only pattern in this post that can answer all ten of the example questions in one query. That’s the differentiation worth building on.





