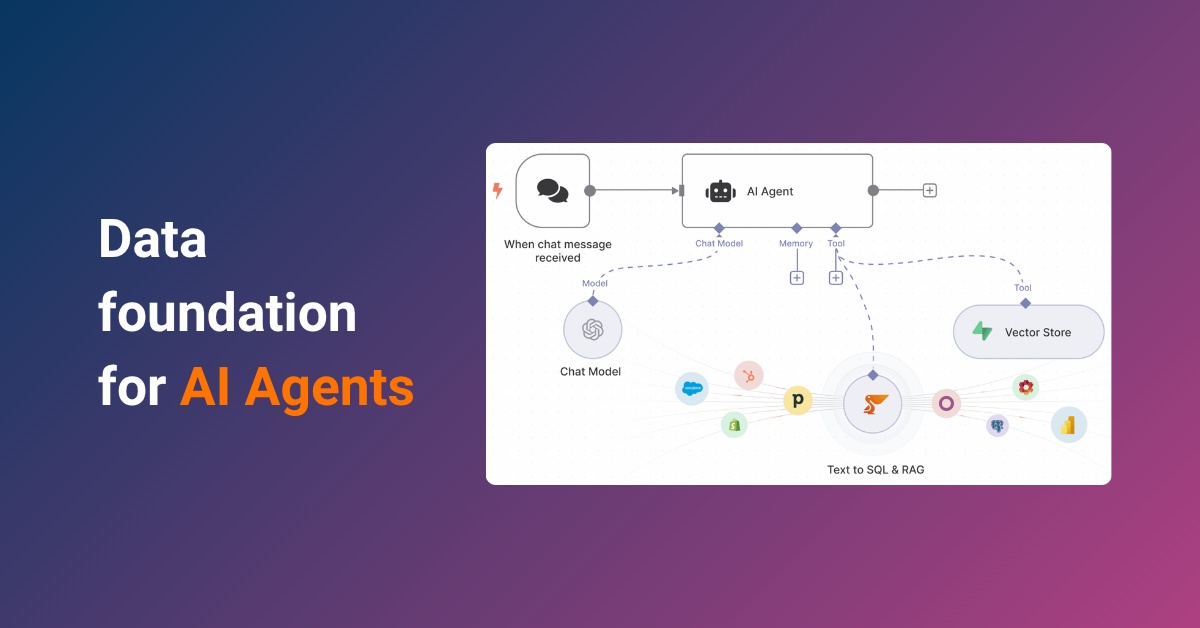








A data warehouse serves as the backbone of modern business intelligence, providing organizations with a centralized system to collect, store, and analyze their vital information. This strategic tool transforms scattered data from various sources into a unified, reliable resource for decision-making.
The data warehousing market is projected to reach USD 85.7 billion by 2032, highlighting its growing importance as organizations seek better ways to manage and analyze their data. From startups to enterprises, businesses worldwide rely on data warehouses to break down information silos, track performance metrics, and identify growth opportunities.
This guide explores the core concepts of data warehousing, its practical benefits, and how it helps businesses turn raw data into valuable insights. Whether you’re evaluating a data warehouse solution or seeking to optimize your existing system, you’ll find clear explanations and actionable knowledge to inform your data strategy.
Understanding the Concept of Data Warehouse
A data warehouse is more than just a large database; it’s a central repository that collects, stores, and manages large volumes of data from various sources within an organization. The concept of data warehouse goes beyond mere storage; it represents a strategic approach to data management that supports business intelligence activities and decision-making processes.
Data warehouses are different from regular databases, which are mainly used for tracking daily transactions. Data warehouses focus on looking at past data to find patterns and trends. This helps businesses understand their customers better, make better products and services, and be more successful.
As companies continue to make decisions based on information, data warehouses will become even more important for companies to succeed. In this blog, we will explore the concept of data warehousing, benefits, and the evolving landscape of this essential technology.
Key Characteristics of the Data Warehouse Concept
- Integrated Data: The data warehouse concept emphasizes the integration of data from multiple, often disparate sources into a coherent whole.
- Subject-Oriented: Unlike operational systems organized around specific applications, data warehouses are structured around major subjects of the enterprise (e.g., customers, products, sales).
- Time-Variant: A core principle of the data warehouse concept is the maintenance of historical data, allowing for trend analysis over time.
- Non-Volatile: Once data enters the warehouse, it should not change. This stability is crucial for consistent reporting and analysis.
- Optimized for Query Performance: The data warehouse concept includes strategies for optimizing data structures and storage for complex queries and analytical processing.
Now that we’ve established the core characteristics, let’s explore how these principles are implemented in the architecture of a data warehouse.
The Architecture of Data Warehouses: A Deeper Dive
Understanding the concept of data warehouse requires a comprehensive knowledge of its architecture. A well-designed data warehouse architecture is crucial for ensuring efficient data integration, storage, and retrieval. Let’s examine each component in detail:
Source Systems:
These are the various operational databases and external data sources that feed into the data warehouse. They can include:
- Transactional databases (e.g., CRM, ERP systems)
- External data providers (e.g., market research data, social media data)
- Flat files and spreadsheets
- IoT devices and sensors
Data Staging Area:
Also known as the “landing zone,” this temporary storage area is where data is cleaned, transformed, and prepared for loading into the main warehouse. Key processes in the staging area include:
- Data cleansing: Correcting errors and inconsistencies
- Data transformation: Converting data into a consistent format
- Data validation: Ensuring data meets quality standards
Central Data Warehouse:
This is the core repository where integrated, historical data is stored. It typically uses a relational database management system (RDBMS) and employs specific design techniques such as:
- Star schema: A design pattern with a central fact table connected to multiple dimension tables
- Snowflake schema: An extension of the star schema with normalized dimension tables
Data Marts:
These are subsets of the data warehouse focused on specific business areas or departments. Data marts can be:
- Dependent: Sourced directly from the central data warehouse
- Independent: Sourced from operational systems or external data
Metadata Repository:
This component stores information about the data within the warehouse, including:
- Business metadata: Definitions, ownership, and usage of data
- Technical metadata: Data types, structures, and relationships
- Operational metadata: ETL job logs, data lineage, and usage statistics
Data Access Tools:
These are the software applications that allow users to interact with the data warehouse. They include:
- Business Intelligence (BI) tools for reporting and dashboarding
- Data mining and predictive analytics tools
- OLAP (Online Analytical Processing) tools for multidimensional analysis
Understanding these components is crucial for grasping the full concept of data warehouse architecture. Now, let’s explore how data flows through this architecture in the ETL process.
ETL Process in Data Warehousing: The Backbone of Data Integration
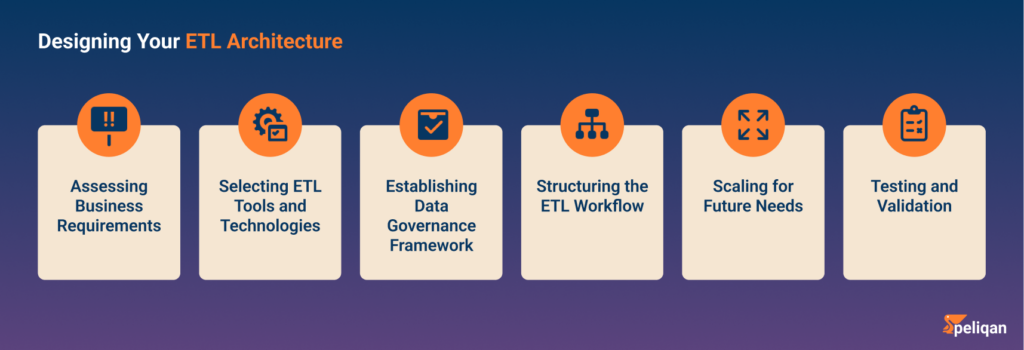
The ETL (Extract, Transform, Load) process is a fundamental concept in data warehousing, serving as the backbone of data integration. Let’s break down each step:
Extract
In this phase, data is extracted from various source systems. This can involve:
- Full extraction: Capturing all data from the source
- Incremental extraction: Capturing only new or changed data since the last extraction
- Change data capture (CDC): Identifying and extracting only the changes made to source data
Transform
The transformation phase is where data is cleaned, standardized, and transformed to fit the data warehouse schema. Key transformation tasks include:
- Data cleansing: Correcting errors, handling missing values, and removing duplicates
- Data standardization: Ensuring consistent formats for dates, currencies, and other data types
- Data enrichment: Adding derived or calculated values
- Data aggregation: Summarizing data for improved query performance
Load
In the final phase, the transformed data is loaded into the data warehouse. This can be done in two ways:
- Batch loading: Data is loaded in scheduled batches, typically during off-peak hours
- Real-time loading: Data is continuously loaded as it becomes available
The ETL process ensures that the data in the warehouse is consistent, accurate, and ready for analysis. With clean, integrated data in place, organizations can reap numerous benefits from their data warehouse implementation.
Benefits of Implementing a Data Warehouse
The concept of data warehouse offers numerous benefits to organizations, driving significant business value. Let’s explore these advantages in detail:
Improved Decision Making
By providing a single source of truth, data warehouses enable more informed, data-driven decisions. This leads to:
- Faster response to market changes
- More accurate forecasting and planning
- Better resource allocation
Enhanced Business Intelligence
Data warehouses support complex queries and analytics, powering sophisticated BI tools. This enables:
- Creation of comprehensive dashboards and reports
- Ad-hoc analysis for answering specific business questions
- Discovery of trends and patterns in business data
Historical Intelligence
The ability to analyze historical trends helps in:
- Forecasting future trends
- Identifying seasonal patterns
- Understanding long-term business performance
Data Quality and Consistency
The ETL process improves overall data quality and ensures consistency across the organization, resulting in:
- Increased trust in data
- Reduced errors in reporting and analysis
- Better compliance with data regulations
Separation of Analytics from Operations
By offloading analytical queries, data warehouses prevent performance impacts on operational systems. This leads to:
- Improved performance of transactional systems
- Ability to run complex queries without affecting day-to-day operations
- Better scalability for both operational and analytical workloads
These benefits highlight why the concept of data warehouse has become integral to modern business intelligence strategies. To further illustrate the versatility of data warehouses, let’s compare different types of data warehouse implementations.
Types of Data Warehouses: Choosing the Right Approach
As the concept of data warehouse has evolved, several types of implementations have emerged to meet diverse business needs. Understanding these types can help organizations choose the right approach for their data strategy.
| Type | Description | Pros | Cons | Best For |
|---|---|---|---|---|
| Enterprise Data Warehouse (EDW) | Centralized warehouse that serves the entire organization | – Single source of truth – Comprehensive data integration – Supports cross-functional analysis |
– Complex implementation – Higher initial cost – Longer time to value |
Large enterprises with diverse data needs |
| Data Mart | Subset of a data warehouse focused on specific business areas | – Faster implementation – Lower cost – Tailored to specific department needs |
– Potential for data silos – Limited cross-functional analysis – May lead to data redundancy |
Organizations needing quick solutions for specific departments |
| Virtual Data Warehouse | Provides a logical view of data without physical data movement | – Reduced data duplication – Lower storage costs – Real-time data access |
– Performance can be slower – Complex query optimization – Dependency on source system availability |
Organizations with distributed data sources and real-time analytics needs |
| Cloud Data Warehouse | Data warehouse hosted and managed in the cloud | – Scalability and flexibility – Lower upfront costs – Automatic updates and maintenance |
– Data security concerns – Potential for vendor lock-in – Network latency issues |
Organizations seeking scalability and reduced IT overhead |
This table provides a quick comparison of different data warehouse types, helping organizations understand which approach might best suit their needs. As we can see, the concept of data warehouse has evolved to accommodate various business requirements and technological advancements.
Data Warehouse Vendors
We’ve discussed the benefits of data warehouses and how they can help businesses make better decisions. Now, let’s take a look at some of the top data warehouse vendors in the market today. These vendors offer a variety of features and capabilities to meet the needs of businesses of all sizes.
Here is a list of the top 5 data warehouse vendors along with a few lines of description for each:
1. Snowflake
Snowflake is a cloud-based data warehouse that is known for its scalability and performance. It is a popular choice for businesses of all sizes, including enterprises. Snowflake is easy to use and can be deployed in a matter of minutes. It also offers a variety of features, such as real-time analytics and data sharing.
2. Databricks
Databricks was founded by the creators of Apache Spark. Databricks is more of a data lake than a data warehouse, we’ll talk more about the differences below. Databricks processes data with Spark, which allows it to process large amounts of data in parallel.
3. Amazon Redshift
Amazon Redshift is a cloud-based data warehouse that is part of the Amazon Web Services (AWS) platform. It is a powerful and scalable data warehouse that is popular for businesses that are already using other AWS services. Redshift is easy to use and offers a variety of features, such as real-time analytics and data sharing.
4. Google BigQuery
Google BigQuery is a cloud-based data warehouse that is part of the Google Cloud Platform (GCP) platform. It is a powerful and scalable data warehouse that is popular for businesses that are already using other GCP services. BigQuery is easy to use and offers a variety of features, such as real-time analytics and data sharing.
5. Microsoft Azure Synapse Analytics
Azure Synapse Analytics is a cloud-based data warehouse that is part of the Microsoft Azure platform. It is a powerful and scalable data warehouse that is popular for businesses that are already using other Azure services. Synapse Analytics is easy to use and offers a variety of features, such as real-time analytics and data sharing.
Pro tip:
Peliqan.io is a user-friendly all-in-one data platform that empowers business teams of all sizes, from startups to enterprises, to seamlessly connect to any data source with the help of 100+ pre-built connectors and combine data from various sources, without the need for a data engineer.
Peliqan.io connects to your existing data warehouse (e.g. Snowflake) and provides a built-in data warehouse for companies that desire an all-in-one solution.
Peliqan’s intuitive spreadsheet-like interface makes it easy for business users to clean, edit, and transform data, while power users can leverage SQL and developers can utilize low-code tools to build interactive data apps, implement writebacks, and apply machine learning capabilities.
Difference between Data Warehouse, Data Lake & Data Lakehouse
|
Feature |
Data Warehouse |
Data Lake |
Data Lakehouse |
| Purpose | Store and analyze structured data for business intelligence and reporting | Store raw, unstructured data for machine learning and predictive analytics | Store and manage both structured and unstructured data for a variety of use cases |
| Strengths | High data quality Efficient query performance Strong data management |
Can store any type of data Low-cost storage Ideal for complex data processing |
Can store any type of data High data quality Efficient query performance Strong data management |
| Weaknesses | Does not handle raw or unstructured data Expensive to maintain Not ideal for complex data processing |
Poor data quality Less efficient query performance Weak data management |
Emerging technology More expensive than data lakes |
Data warehouses, data lakes, and data lakehouses are all important tools for data analytics. The best data storage architecture for you will depend on your specific needs. If you need to store and analyze structured data, then a data warehouse is a good choice. If you need to store and analyze raw, unprocessed data, then a data lake is a good choice. And if you need to store and analyze both structured and unstructured data, then a data lakehouse is a good choice.
How can a data warehouse help your business to gain a competitive edge?
Data warehouses are at minimum the source of data for BI tools. Analytics (building dashboards, reports etc.) is typically done in a BI tool such as Microsoft Power BI, Qlik, Tableau or Metabase. These tools can connect directly to a source, but by using a data warehouse, a future proof data strategy is deployed that allows organizations to start doing more with their data. This can include data activation, reverse ETL (writing data back into business applications), applying machine learning models for predictions, building data products, setting up data APIs for external partners etc.
Peliqan’s data warehouse capabilities let you seamlessly integrate data from diverse sources, cleaning, transforming, and organizing it into a unified, accessible format. This unified view is the key to unlocking insights that were previously hidden in siloed systems.
So, how exactly does the Peliqan data warehouse help you gain a competitive edge? Peliqan provides all the components needed to implement data activation:
- Connectors: Peliqan provides connectors to a wide range of data sources including databases, business applications (CRM, accounting, ERP etc.), APIs, cloud storage, files, SFTP etc.
- Peliqan makes it easy to explore, transform and combine your data in a spreadsheet interface. Power users can use magical SQL.
- Peliqan provides a low-code visual UI to implement data activation flows.
Peliqan is used for a wide range of use cases, helping companies to explore the possibilities of AI, setting up data syncs between business applications and exchanging data with partners.
Conclusion: Data Warehouses – A Catalyst for Growth
The concept of data warehouse represents a powerful approach to data management that can transform how organizations leverage their information assets. By providing a centralized, integrated view of enterprise data, data warehouses enable deeper insights, better decision-making, and ultimately, a significant competitive advantage in today’s data-driven business landscape.
As data continues to grow in volume and importance, understanding and implementing the concept of data warehouse will be crucial for organizations aiming to thrive in the digital age. Whether you’re just starting to explore data warehousing or looking to optimize your existing implementation, embracing this concept can open up new possibilities for data-driven success.