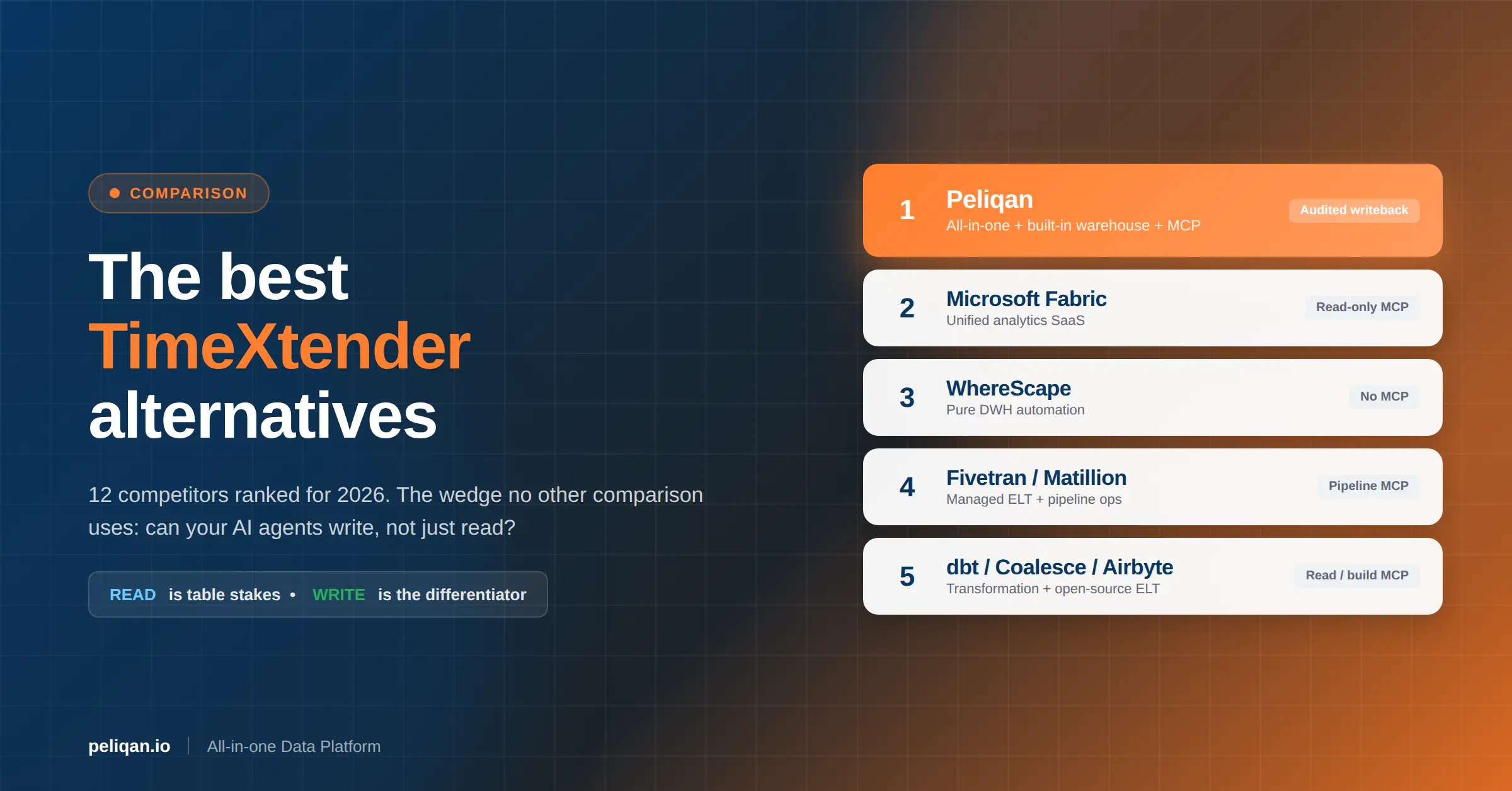
Choosing from the long list of data warehouse tools is harder in 2026 than ever, because the category now spans cloud-native warehouses, lakehouses, enterprise systems, and all-in-one platforms that each suit a different team. This guide compares the top 15 data warehouse tools by category, with an honest read on strengths, trade-offs, and pricing model, plus a framework to pick the right one for your stack.
A data warehouse sits at the centre of every serious analytics, BI, and AI initiative. Get the platform right and queries are fast, data is trusted, and AI agents have clean entities to reason on. Get it wrong and you inherit runaway compute bills or a system your team cannot use. The first step is knowing which category you actually need, because a cloud-native warehouse, a lakehouse, and an in-memory enterprise system are not interchangeable.
What to look for in a data warehouse tool
A data warehouse tool collects, stores, and serves large volumes of structured and semi-structured data from many sources for analysis. Before comparing products, weigh these factors. For the underlying concepts, our guide to data warehouses covers the fundamentals.
Selection criteria that matter in 2026
- Scalability: can it handle today’s volume and scale elastically as you grow, without downtime?
- Performance: fast query processing and concurrency for many users at once.
- Ease of use: the learning curve, the interface, and how quickly a team gets productive.
- Integration: compatibility with your sources, BI tools, and pipelines through pre-built connectors.
- Cost behaviour: not just the headline rate but how cost moves as storage, compute, and queries grow.
- Security and compliance: whether it meets your data residency and regulatory needs.
- Deployment model: cloud, on-premises, or hybrid, and how much control each gives you.
- AI readiness: whether the platform can serve governed data to AI agents and assistants cleanly.
The categories of data warehouse tools
The 15 tools below fall into six groups. Identify your category first, then shortlist within it. This avoids comparing a serverless cloud warehouse against an in-memory enterprise system as if they were the same purchase.
Cloud-native data warehouses
1. Snowflake
Snowflake is a cloud-native warehouse that separates storage and compute, so you scale and pay for each independently. Familiar SQL and an ultra-scalable architecture make it a strong fit for organisations with growing datasets, and it has native support for semi-structured data like JSON and Avro.
Trade-off: pricing can get complex on large deployments and compute cost climbs quickly under heavy use. If you are weighing it against an all-in-one approach, see our Peliqan vs Snowflake comparison. You can also feed Snowflake from other systems using the Peliqan Snowflake connector.
2. Google BigQuery
BigQuery is a serverless warehouse with pay-per-use billing that eliminates infrastructure management. It handles massive datasets with fast query speeds and ships built-in machine learning and generative AI features, so you can run advanced analytics without moving data. Peliqan connects through its BigQuery connector for import and transformation.
Trade-off: pay-per-query plus separate storage billing can become expensive without monitoring, and the advanced AI features carry their own learning curve.
3. Amazon Redshift
Redshift is a fully managed, petabyte-scale warehouse built for the AWS ecosystem, with automatic concurrency scaling for hundreds of simultaneous queries. It is cost-efficient for analysing large datasets already in S3 and familiar to AWS users. The Peliqan Redshift connector bridges it to other tools.
Trade-off: it may need tuning for peak performance, and it is strongest when you are already committed to AWS.
4. Microsoft Azure Synapse and Microsoft Fabric
Azure Synapse unifies data warehousing and big data analytics inside Azure. Microsoft has since folded analytics into Microsoft Fabric, a unified platform that combines warehousing, data engineering, and Power BI under one umbrella, which is now one of the most discussed enterprise choices for Microsoft-centric teams.
Trade-off: the breadth brings a steeper learning curve, and cost depends on the mix of Azure and Fabric services you use. For teams comparing a single Microsoft stack against an independent platform, our Peliqan vs Fabric breakdown is a useful reference.
Lakehouse platforms
5. Databricks
Databricks pioneered the lakehouse, blending warehouse and data lake capabilities on the open Delta Lake format. In 2026 it is widely seen as one of Snowflake’s main competitors, having invested heavily in SQL performance and BI integrations. Organisations building AI workloads or unifying data engineering and analytics often choose it as a warehouse alternative.
Trade-off: the platform is powerful but broad, and getting full value usually requires data engineering skill rather than a pure SQL analyst team.
New-wave and specialised tools
6. ClickHouse and 7. Firebolt
These tools challenge traditional warehouse assumptions by focusing narrowly on speed. ClickHouse is an open-source columnar database built for extreme real-time analytical performance and high-concurrency dashboards. Firebolt targets sub-second analytics on large datasets. Both suit teams whose primary requirement is raw query speed rather than a broad feature set.
Trade-off: the narrow focus means fewer built-in governance, transformation, and ecosystem features than the major cloud warehouses.
Enterprise and on-premises warehouses
8. Teradata
Teradata is an enterprise-grade warehouse for mission-critical deployments, with strong security, high availability, and an architecture that handles enormous data volumes. Its security features make it a fit for organisations with sensitive data.
Trade-off: higher cost than cloud-native options and a complex setup that needs significant IT expertise.
9. Oracle Autonomous Data Warehouse
Oracle Autonomous Data Warehouse offers self-driving warehousing with automated management in the Oracle Cloud, using machine learning for workload optimisation. The automation simplifies day-to-day warehouse operations for Oracle Cloud users.
Trade-off: potential vendor lock-in and fewer customisation options than open-source alternatives.
10. IBM Db2 Warehouse
Db2 Warehouse is a secure, reliable warehouse built to integrate with IBM’s analytics ecosystem, with advanced data governance and the scale to handle complex queries on demanding workloads.
Trade-off: it rewards familiarity with IBM technologies and risks vendor lock-in if you lean on the wider IBM stack.
11. SAP HANA
SAP HANA is an in-memory platform for real-time analytics, tightly integrated with SAP applications and optimised for high-speed processing of transaction data. It is the natural choice for organisations already invested in SAP.
Trade-off: higher cost than cloud options and most valuable inside the SAP ecosystem.
12. Micro Focus Vertica
Vertica is a high-performance columnar warehouse for complex analytical workloads, using advanced compression to query large historical datasets efficiently. It excels at trend analysis over big volumes of historical data.
Trade-off: it needs significant technical expertise and is not built for real-time analytics.
Open-source databases used as warehouses
13. PostgreSQL
PostgreSQL is a powerful open-source relational database that can serve as a cost-effective warehouse for teams with the in-house skill to run it. It pairs a rich feature set for data management with a large, active community. Peliqan can, for example, pull PostgreSQL data into Google Sheets with a one-click connector.
Trade-off: it requires in-house expertise to set up and maintain, and scales less easily than purpose-built cloud warehouses.
14. MariaDB
MariaDB is another open-source relational database used for warehousing, with a familiar SQL interface and high-availability features. It suits teams already invested in the MySQL ecosystem looking for a cost-effective option, with ColumnStore adding analytical capabilities.
Trade-off: like PostgreSQL, it needs in-house expertise and scales less readily than cloud-native warehouses.
15. Cloudera
Cloudera is an open data platform offering a flexible, customisable warehouse that handles diverse data formats across the Hadoop ecosystem. It is a cost-effective alternative to some proprietary options for teams that want to build a data warehouse with full control.
Trade-off: it carries a steeper learning curve and needs in-house expertise for deployment and maintenance.
A note on terminology: NoSQL services like Amazon DynamoDB and multi-model databases like MarkLogic sometimes appear on warehouse lists. They are excellent operational databases, but they are not true analytical warehouses, so treat them as complements rather than direct substitutes for the platforms above.
All-in-one data platforms
The platforms above each cover storage and query. Most teams still need ingestion, transformation, and activation around them, which means stitching together several vendors. All-in-one platforms collapse that stack into one product, which is why teams without a dedicated data engineer increasingly start here.
Peliqan
Peliqan is an all-in-one data platform built for rapid deployment. It connects to your business applications, loads data into a built-in warehouse or your own Snowflake and BigQuery, lets you explore it in a spreadsheet UI with SQL, and supports data activation such as reverse ETL, API publishing, alerts, and scheduled reports.
Where Peliqan fits
The 2026 shift: warehouses as the AI data layer
The biggest change in the category is that the warehouse is becoming the data layer that AI agents reason on. Buyers now weigh whether a platform can expose governed, well-modelled data to assistants through capabilities like text-to-SQL, automatic vectorising for retrieval-augmented generation, and a Model Context Protocol gateway. Clean transformations and trustworthy entities matter more when an agent, not just a dashboard, is the consumer.
This is reshaping selection criteria. A warehouse that is fast but opaque to AI tooling is a weaker 2026 choice than one that surfaces governed data and supports exploration and analysis for both humans and agents. The major cloud warehouses are adding native AI features, and all-in-one platforms are building the AI layer in by default.
Data warehouse tools compared
Integration capability is where many warehouse decisions are won or lost, because the platform has to fit your BI tools, pipelines, and wider ecosystem. This table summarises how the leading tools connect.
Data warehouse tools pricing
Exact figures change often, so the pricing model matters more than any single rate. Cloud-native warehouses like Snowflake, BigQuery, Redshift, and Fabric use pay-per-use models that bill storage and compute or queries separately, which scales with usage but can be hard to predict. Enterprise systems like Teradata, Oracle, and IBM Db2 require upfront licensing and a vendor quote. Open-source options like PostgreSQL, MariaDB, and Cloudera are free to download but carry infrastructure and maintenance costs.
All-in-one platforms take a different route. Peliqan uses fixed monthly plans with a 14-day free trial, so cost stays predictable and is not tied to row volume. See Peliqan’s pricing for current tiers. Whichever you choose, factor in the cost of the data integration tools needed to move data in, plus support, which is bundled with managed cloud services but often community-based for open-source options.
Data warehouse tools in the real world
Features only matter once you see them applied. Industries from retail to healthcare to finance use warehouses to unify scattered systems, then point BI and AI at the result. Our roundup of data warehouse examples covers industry-specific use cases, success stories, and how AI and machine learning are being folded into modern warehouses.
Real-world example: CIC Hospitality
CIC Hospitality unified fragmented data from 50+ sources into one warehouse and now produces real-time, board-level reports, saving 30+ hours per month that used to go into manual Excel consolidation. Read the full case study.
How to choose the right data warehouse tool
Start with your category, then weigh five factors: data volume and complexity, your existing cloud ecosystem, in-house technical expertise, budget and cost model, and security and compliance needs. A team deep in AWS will lean toward Redshift, a Microsoft estate toward Fabric, and an AI-first engineering team toward Databricks. Documentation and support quality, available in the Peliqan docs, also separate a smooth rollout from a stalled one.
If you have dedicated data engineers and specialised scale needs, a best-of-breed cloud warehouse or lakehouse gives the most control. If you want fewer moving parts and faster time to trusted numbers, an all-in-one platform that bundles the warehouse, pipelines, and activation will get you there with less overhead. Match the tool to your team and use case, and the rest of the stack becomes far easier to build.