In today’s data-driven world, organizations are inundated with information from countless sources. To harness the power of this data and transform it into actionable insights, businesses need robust data pipelines.
But what exactly is a data pipeline, and how can you build one effectively? This comprehensive guide will walk you through the essentials of data pipelines, their importance, and a step-by-step approach to building them.
What is a Data Pipeline?
A data pipeline is an automated system that collects, processes, and moves data from various sources to one or more destinations where it can be analyzed and utilized. Think of it as a sophisticated conveyor belt system in a factory, where raw materials (data) are transformed into finished products (insights) through a series of coordinated processes.
Key aspects of data pipelines include:
- Data extraction from multiple sources
- Data transformation and cleaning
- Data loading into target systems
- Automation and scheduling of data flows
- Error handling and monitoring
The Importance of Data Pipelines in Modern Business
Data pipelines play a pivotal role in ensuring that businesses can leverage the vast amounts of data generated every day. Their efficient design and implementation enable organizations to make informed decisions based on accurate, timely information. Below are several key reasons illustrating the significance of data pipelines in modern business:
- Real-time decision making: Data pipelines enable organizations to process and analyze data as it is generated, facilitating timely insights that can directly inform strategic decisions. This immediacy allows businesses to respond swiftly to market changes and operational challenges.
- Data quality and consistency: Automated data pipelines integrate data from diverse sources while employing rigorous transformation and validation processes. This ensures that the data remains accurate, consistent, and reliable throughout its lifecycle, ultimately enhancing its applicability for analysis and decision-making.
- Scalability: An effective data pipeline is designed to accommodate increasing data volumes and source complexities without degradation in performance. This inherent scalability positions organizations to expand their data capabilities seamlessly as business needs evolve.
- Competitive advantage: Organizations that deploy advanced data pipelines gain the ability to derive insights faster than their competitors. By leveraging data effectively, they can identify trends and opportunities, leading to more informed and proactive business strategies.
- Resource optimization: Efficient data pipelines automate routine data tasks, freeing up valuable engineering and analytical resources. This optimization allows teams to focus on higher-value activities, enhancing productivity and innovation within the organization.
Understanding the fundamental components of a data pipeline is essential for building effective and resilient systems that can adapt to the diverse needs of modern businesses. In the next section, we will delve into the key components that comprise a data pipeline, providing a detailed analysis of each element’s role and significance in the data processing workflow.
Components of a Data Pipeline
A well-constructed data pipeline is composed of several integral components, each playing a crucial role in the effective management of data flow. Let’s take a look at the 7 key data pipeline components in detail:
1. Data Sources
Data pipelines originate from various data sources, which can include databases, cloud storage, APIs, web applications, and sensors. The nature of these sources can range from structured data (like relational databases) to unstructured data (such as log files and multimedia). Identifying and integrating diverse data sources is essential for creating a comprehensive view of the relevant information.
2. Data Ingestion
Data ingestion refers to the processes involved in collecting data from the sources identified. This can be done through batch processing, where data is collected at specified intervals, or via real-time streaming, which captures data instantaneously as it becomes available. Effective ingestion techniques are critical in ensuring that the data is timely and accurately reflects the current state of affairs.
3. Data Transformation
Once ingested, data often requires transformation to ensure its suitability for analysis. Transformation tasks may include cleaning (removing duplicates and correcting errors), formatting (standardizing date formats and units), and enriching (adding derived metrics or external data). This component is vital for enhancing data quality and ensuring that the final dataset is reliable and actionable.
4. Data Storage
After transformation, the data needs to be stored in a target system where it can be easily accessed and analyzed. Various storage solutions are available, including data warehouses for structured data, data lakes for unstructured data, and traditional databases for transactional data. The choice of storage technology should consider factors such as data volume, access speed, and analytical needs.
5. Data Monitoring and Maintenance
To ensure the long-term effectiveness of a data pipeline, continuous monitoring and maintenance are necessary. This includes performance metrics (to ascertain processing speed), error logging (to capture issues that require troubleshooting), and system health checks (to ensure that all components are functioning as expected). Regular maintenance keeps the pipeline optimized and helps identify areas for improvement or upgrade.
With data breaches and regulatory requirements becoming increasingly prevalent, security and compliance must be integral components of any data pipeline. This encompasses implementing data encryption, access controls, and adhering to data protection regulations, such as GDPR or NIS2. Keeping data secure not only protects organizational assets but also builds trust with users and stakeholders.
These components work collaboratively to establish a streamlined process that transforms raw data into valuable insights, enabling businesses to leverage their data effectively for strategic advantages.
Types of Data Pipelines
Understanding the distinctions between various types of data pipelines is crucial for organizations seeking to optimize their data processing strategies. Here, we will explore three critical comparisons:
| Data Pipeline Types | Description | Use Cases |
|---|---|---|
| Batch Data Pipeline | Processes large volumes of data at scheduled intervals. This method is suitable for scenarios where real-time data processing is not critical. | Monthly reporting, payroll software, and historical data analysis. |
| Real-time Data Pipeline | Captures and processes data as it is generated, allowing for immediate insights and quick decision-making. This approach is essential when speed is critical. | Fraud detection, live social media analytics, and IoT sensor data processing. |
| ETL (Extract, Transform, Load) | Data is extracted from various sources, transformed to meet analysis requirements, and loaded into a destination system, typically a data warehouse. | Traditional data warehousing scenarios, regulatory compliance reporting. |
| ELT (Extract, Load, Transform) | Data is first extracted from sources and loaded into a storage system, followed by transformations. This method capitalizes on the power of modern data lakes. | Big data environments, real-time analytics where transformation flexibility is key. |
| Cloud Data Pipeline | Operates in a cloud environment, offering scalability, flexibility, and reduced maintenance overhead. Typically leverages cloud-native services. | Companies using SaaS applications, distributed teams needing remote access to data. |
| On-premises Data Pipeline | Operates within an organization’s local infrastructure, providing greater control and security over data. However, it requires substantial investment in hardware. | Companies with strict data governance policies, legacy system integration. |
By comprehensively understanding these distinctions, organizations can strategically select the type of data pipeline that aligns with their operational requirements and analytical goals.
Building Data Pipelines: 11 Step Guide
Building a robust data pipeline requires a systematic approach to ensure that all aspects of data processing are addressed efficiently. Below is a detailed explanation of each step involved in creating a data pipeline.
Step 1: Define Your Goals and Requirements
Before beginning the construction of a data pipeline, it is crucial to clearly outline the objectives and requirements of the system. This includes identifying the types of data to be processed, determining the expected outcomes, and understanding how the insights will be utilised within the organization. Establishing these parameters ensures that the pipeline aligns with business goals from the onset.
Step 2: Choose Your Data Pipeline Architecture
Deciding on the appropriate architecture is a pivotal next step. Organizations must choose between batch and real-time processing, as well as between ETL and ELT methodologies based on their specific use cases. The selected architecture should accommodate the expected data volumes and speed of processing required to meet analytical needs.
Step 3: Select Your Tools and Technologies
With the architecture defined, selecting the right tools and technologies is essential. This may include data integration platforms, data storage solutions, and analytical tools that facilitate efficient data processing and visualization. The choice should be influenced by compatibility, scalability, and user needs.
Step 4: Design the Data Flow
Designing an efficient data flow encompasses mapping out how data will move through the pipeline. This includes specifying sources, transformation processes, storage locations, and the final destination of the data. A well-designed flow will facilitate seamless data movement and reduce potential bottlenecks.
Step 5: Implement Data Extraction
The next step involves implementing the data extraction process, which is the method by which data is gathered from various sources. This could be achieved through API calls, database queries, or file imports, depending on the nature of the data sources identified during the planning phase.
Step 6: Implement Data Transformation
Following extraction, the data must undergo transformation to enhance its quality and usability. Implementing this step involves applying the necessary cleaning and formatting procedures to prepare the data for analysis. Ensuring that transformations are automated can significantly enhance efficiency.
Step 7: Implement Data Loading
Once the data is transformed, it must be loaded into the chosen storage solution. This step requires careful consideration of how the data is structured and how it will be accessed for analysis. This may involve batch loading for large datasets or continuous loading in real-time systems.
Step 8: Set Up Orchestration and Scheduling
Orchestration involves automating the workflow to ensure that each component of the pipeline operates in an optimized sequence. Scheduling is crucial for batch processes, specifying when data extraction, transformation, and loading tasks should occur. Effective orchestration ensures that data is consistently updated and available for analysis.
Step 9: Implement Monitoring and Logging
To maintain the integrity and performance of the data pipeline, implementing monitoring and logging practices is essential. This includes tracking system performance, error rates, and processing times. Monitoring tools can provide valuable insights into the health of the pipeline and highlight areas needing attention.
Step 10: Test and Validate
Thorough testing and validation are necessary to ensure the data pipeline functions as intended. This step involves checking for data accuracy, ensuring that data transformations are correctly implemented, and confirming that the pipeline meets all defined requirements. Regular testing helps identify and address issues proactively.
Step 11: Deploy and Maintain
Once the pipeline has been tested and validated, it is ready for deployment. Continuous maintenance is critical to ensure the pipeline evolves with changing data needs and technological advancements. Maintaining the pipeline involves regular updates, monitoring for performance issues, and adapting to new requirements to sustain efficiency and reliability.
By following these structured steps, organizations can successfully build data pipelines that enable them to harness their data effectively, derive actionable insights, and ultimately achieve their strategic goals.
Tools and Technologies for Data Pipeline Development
Choosing the right tools and technologies is crucial for effective data pipeline development. A variety of platforms and frameworks are available to facilitate the creation, management, and optimization of data pipelines. Below are some key tools, that organizations can leverage:
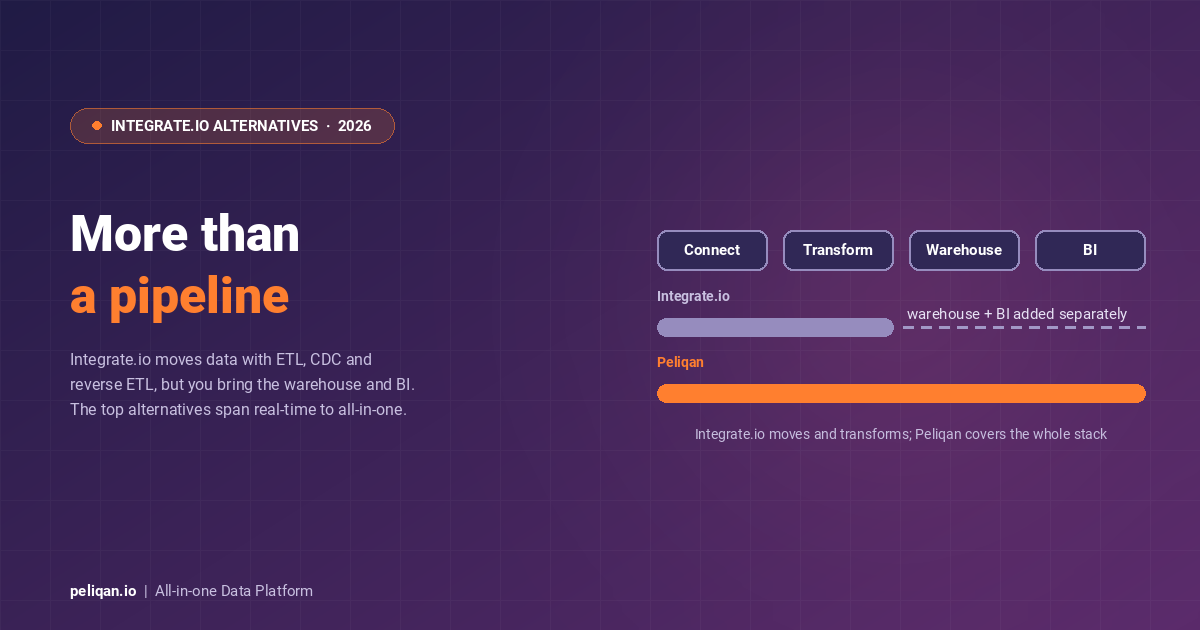
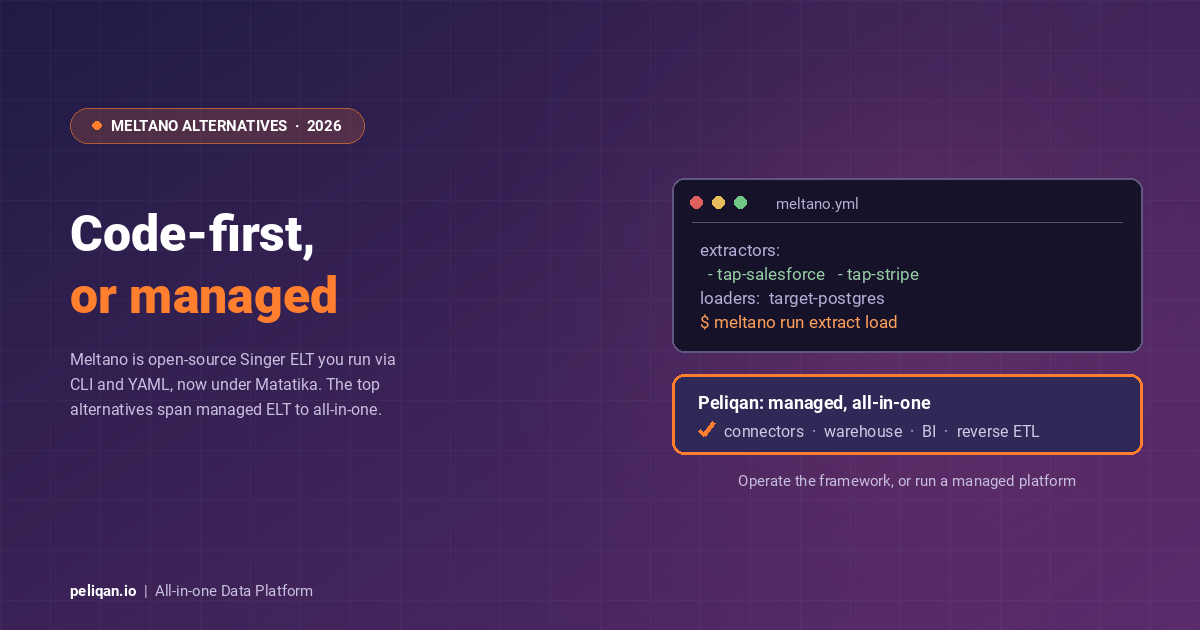
- Peliqan: An all-in-one data platform offering an intuitive visual interface and zero-code approach. It features a spreadsheet UI, “magical SQL” for data exploration, and low-code Python capabilities for developers, making it accessible to users of all technical levels.
- Apache Airflow: A powerful open-source platform for building complex data pipelines. It offers a Python-based syntax for granular control and customization, along with robust scheduling features and a vibrant ecosystem of plugins and connectors.
- Hevo Data: A platform known for its real-time data streaming capabilities, enabling continuous data flow into data warehouses. It supports a wide range of data sources and offers pre-built connectors for popular cloud applications, simplifying data storage and management.
- AWS Glue: A serverless data integration service designed specifically for the AWS cloud platform. It automates data extraction, transformation, and loading while leveraging AWS resources and services, eliminating the need for infrastructure management.
- Stitch Data: An efficient data integration platform focused on cloud analytics platforms like Looker and Google Analytics. It streamlines data ingestion from various sources and automates schema management, making it ideal for business intelligence and data visualization users.
- Fivetran: A fully managed ELT (Extract, Load, Transform) platform that simplifies data integration with popular cloud data warehouses. It excels in data schema management, change data capture, and automatic updates, ensuring data accuracy and freshness.
- Matillion: A robust ETL/ELT tool catering to complex data integration needs. It offers both a visual designer and coding support, capable of handling large-scale data volumes and complex transformations, making it suitable for enterprise-level data architectures.
Selecting the appropriate data pipeline tools is essential for establishing an efficient data pipeline architecture, as they can facilitate data ingestion, transformation, and orchestration while ensuring scalability, performance, and security.
Conclusion
Building an effective data pipeline is crucial for organizations looking to harness the full potential of their data. By following a structured approach, implementing best practices, and leveraging the right tools, businesses can create robust pipelines that transform raw data into valuable insights.
Remember, a well-designed data pipeline is not just a technical asset—it’s a strategic one that can drive innovation, improve decision-making, and ultimately contribute to the overall success of your organization. Start building your data pipeline today and unlock the true power of your data.
Among the myriad of tools available, Peliqan stands out due to its user-centric design and powerful capabilities for data orchestration. As organizations continue to navigate an increasingly data-driven landscape, leveraging tools like Peliqan will be essential for achieving operational excellence and sustaining growth in the forthcoming era of analytics.