






Data platforms and iPaaS tools are widely used to implement ETL pipelines in all kinds of flavours. These pipelines take data from various sources – for example business applications – and centralise the data in a data warehouse. Once the data is in a data warehouse, the next step is often a “reverse” ETL flow where data is synced back into business applications.
Furthermore, the data warehouse can be used to set up alerting rules for business teams, it can be used to produce custom reports and a data warehouse can even feed data into an in-house AI chatbot (using an LLM).
It’s fair to say that there are many different use cases for data integration and for data activation and it’s clear that both data platforms and iPaaS tools play a crucial role in all of these data use cases.
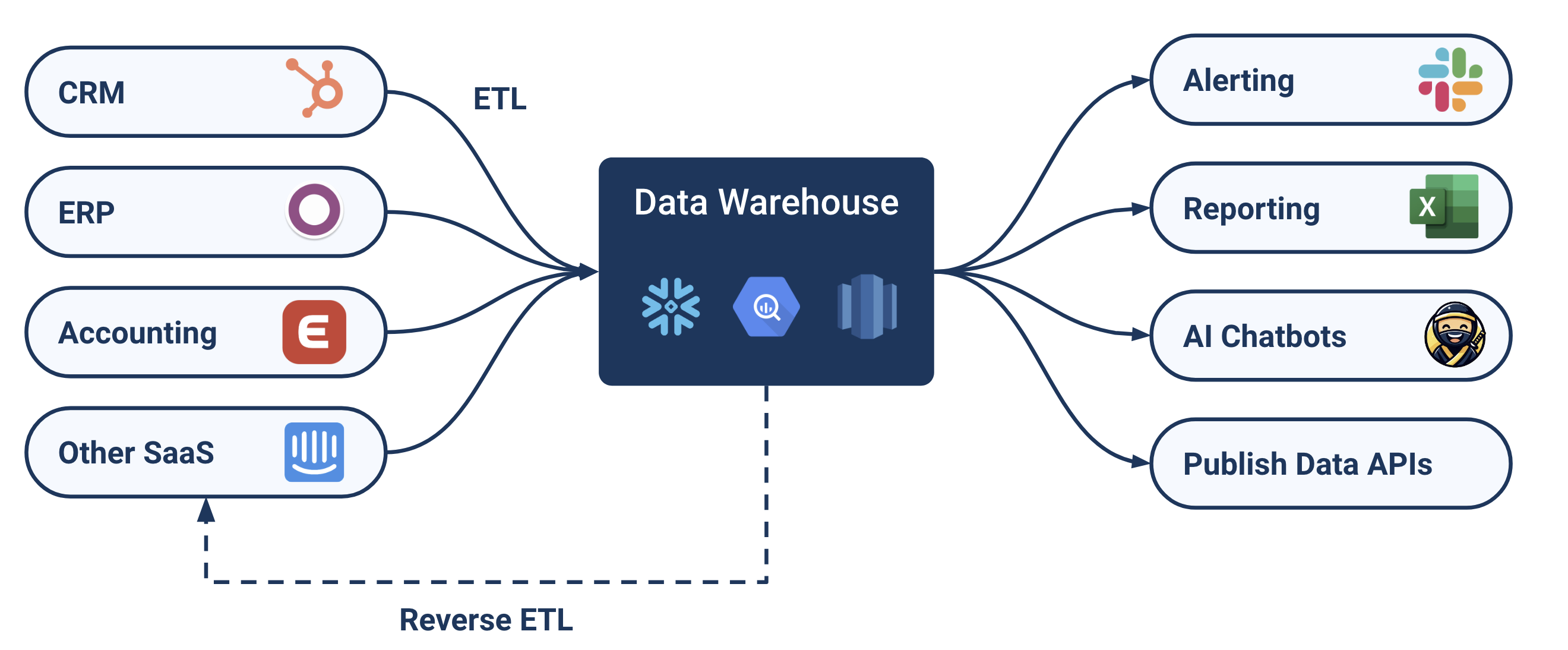
The challenge with many of the data platforms and iPaaS tools on the market is that they are either too complex to use, or that they are too simplistic and limited in functionality, in order to implement specific data solutions:
- Data platforms are often geared towards the initial ETL data loading step, and do not provide capabilities to e.g. set up a reverse ETL flow, set up business alerts or to “activate” the data, e.g. share data via API endpoints, set up chatbots, build & distribute custom reports etc.
- iPaaS platforms on the other hand, are not equipped to handle large amounts of data and are not capable of handling relational data and data-centric implementations.
The solution: low-code Python
We can distinguish two major activity types in both data integration and data activation:
- Data processing (pipelines, transformations, aggregations, joins etc) with SQL as the incumbent language
- Implementation of business logic & automation where Python is the most popular scripting language
What has been lacking on the market is a data platform or iPaaS that seamlessly integrates SQL and Python into a single unified workbench. That’s why our team has built Peliqan.io, a unique approach to data integration and data activation that allows users to seamlessly combine SQL and low-code Python.
In this article we’ll dive into the concept of low-code Python, what it means and how it’s different from “classic” coding in Python.
What is low-code Python ?
Low-code basically means that you need less lines of code compared to “classic” coding, which makes the code easier to write, easier to understand and easier to maintain.
Low-code Python allows users to use one of the most popular scripting languages in the world – Python – with all the benefits of the low-code paradigm. Low-code Python saves time and allows users with a less technical background to implement the solutions that they need.
Difference between low-code and no-code
Many iPaaS platforms use a no-code approach for their main UI, which usually looks like workflows with blocks that users click together in a drag & drop interface. This approach is great for various automation flows that perform “if this then that” logic. However, for data-centric use cases, the no-code approach tends to create very complex workflows with hundreds of blocks, which defeats the purpose of having a visual representation.
That’s why a low-code approach combines the best of both worlds: users do not have to be full-fledged developers and can implement data integration solutions with small scripts, without being hindered by the inherent limitations of a visual workflow editor.
Low-code Python: 3 pillars
Peliqan’s low-code Python for data integration and data activation consists of 3 main pillars:
- A framework
- A toolset
- Coding support features
We’ll discuss each of these pillars in the next paragraphs.
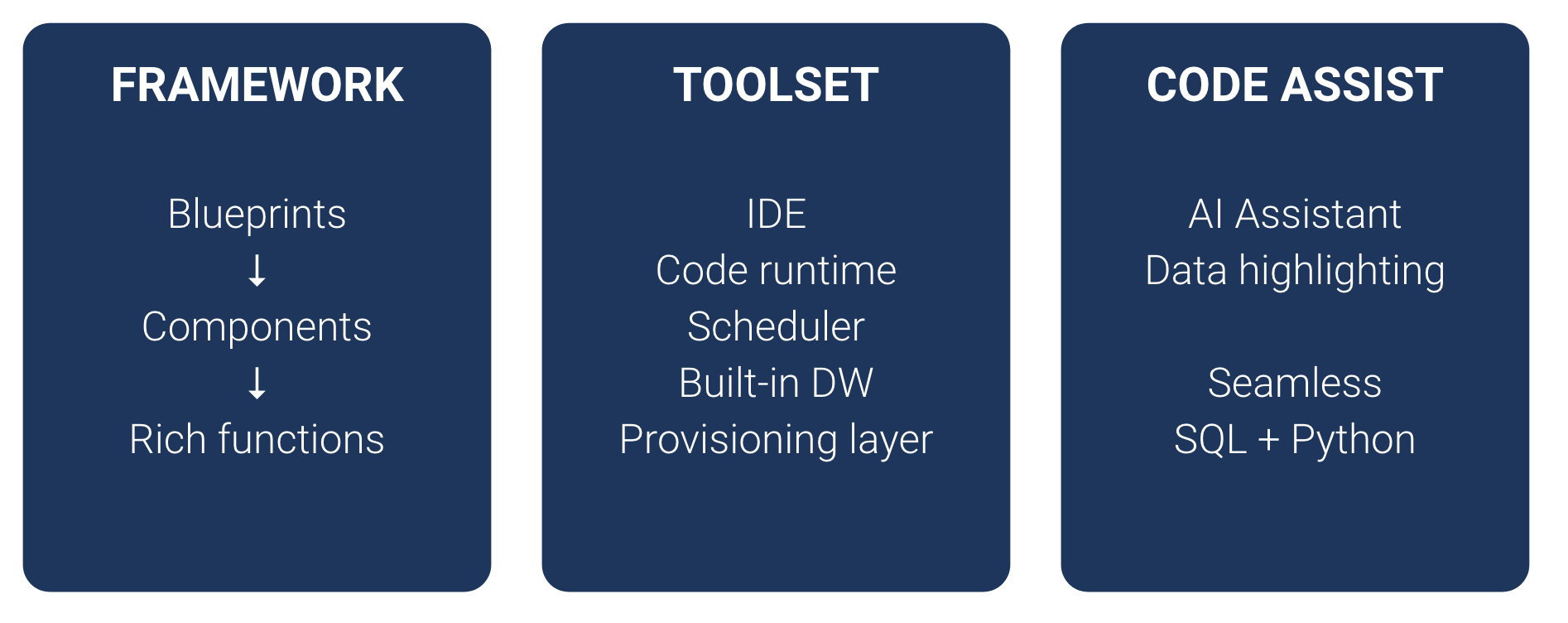
The framework
The framework provides patterns or “blueprints” on how to implement various data integration use cases. For example if you want to set up a data sync from a source to a destination, you have to think about various aspects such as processing the source data incrementally and doing “upserts” in the target to avoid duplicates. The Peliqan.io framework provides blueprints for such a data synchronisation so that the correct pattern is implemented from the start.
The blueprints are implemented using a set of components and the components provide rich functions so that common actions can be performed with only one line of code.
A great example is the “upsert” when writing data to a target, for example a CRM system. An upsert means that you either add a new record if it does not exist or update the existing record if it does. The upsert requires a lookup first and then performs the insert or update. Peliqan allows you to perform an upsert to over 100 target systems (DB’s, ERP, CRM, accounting etc.) with just one line of code. This makes your code concise, easy to understand and you don’t have to reinvent the wheel.
Here are a few example of components that Peliqan.io provides out-of-the-box as part of its low-code Python solution:
- Peliqan module “pq”
- Streamlit
- API wrappers for SaaS (ERP, CRM, accounting etc.)
Peliqan “pq” module
The Peliqan module provides a wide range of functions to work with data:
- Handling data in the built-in data warehouse or a connected data warehouse (Snowflake, Bigquery etc.)
- Fetching data as a Pandas dataframe or as a simple list of objects (dicts)
- Fetching data via Peliqan’s built-in federated query engine (Trino)
- Handling SFTP connections
- Managing state, for example for incremental data syncs
- Handling data pipelines: refreshing pipelines etc.
Streamlit
Streamlit is a wonderful module for data-centric user interaction. Streamlit is built-in into Peliqan and allows you to build data apps with just a few lines of code. Streamlit comes with a wide range of UI components, for example input fields, dropdows, data visualization (charts), components for a Chatbot and much more.
API wrappers
One of the most unique features of Peliqan’s low-code Python environment is the API wrappers for 100+ business SaaS applications. These API wrappers allow you to interact with SaaS APIs with a single line of code. The wrapper will handle all the specifics of the API:
- Authentication, including refreshing oAuth tokens
- Paging
- Rate limiting
- Building up the full API call including the correct headers and payload body
- Etc.
The toolset
Peliqan.io provides a unified workbench to write, test, deploy and maintain low-code Python scripts and SQL queries for data integration and data activation, all in one beautiful web-based environment. SQL and Python can be seamlessly combined.
Peliqan provides a web-based IDE to write scripts, run them and expose scripts as API endpoints. Scripts can be scheduled to run e.g. every minute, hour or every day. Logs are automatically stored for every run. Peliqan can receive and queue incoming webhooks from any source, without the need for any additional configuration.

Next to the core Python and SQL IDE, Peliqan also provides a Marketplace that allows for single click deployment of common building blocks that are needed in a data-centric project. The Marketplace is essentially a provisioning layer for infrastructure, so that users do not lose time figuring out how to install, configure and host tools that they need such a an SFTP server, a vector database, a BI tool such as Metabase or Superset, a Jupyter notebook or a search engine such as ElasticSearch.
Coding support features
In order to help users write correct scripts, Peliqan provides various built-in aids to support you:
- AI assistant
- Data preview on hover in code
- Visibility
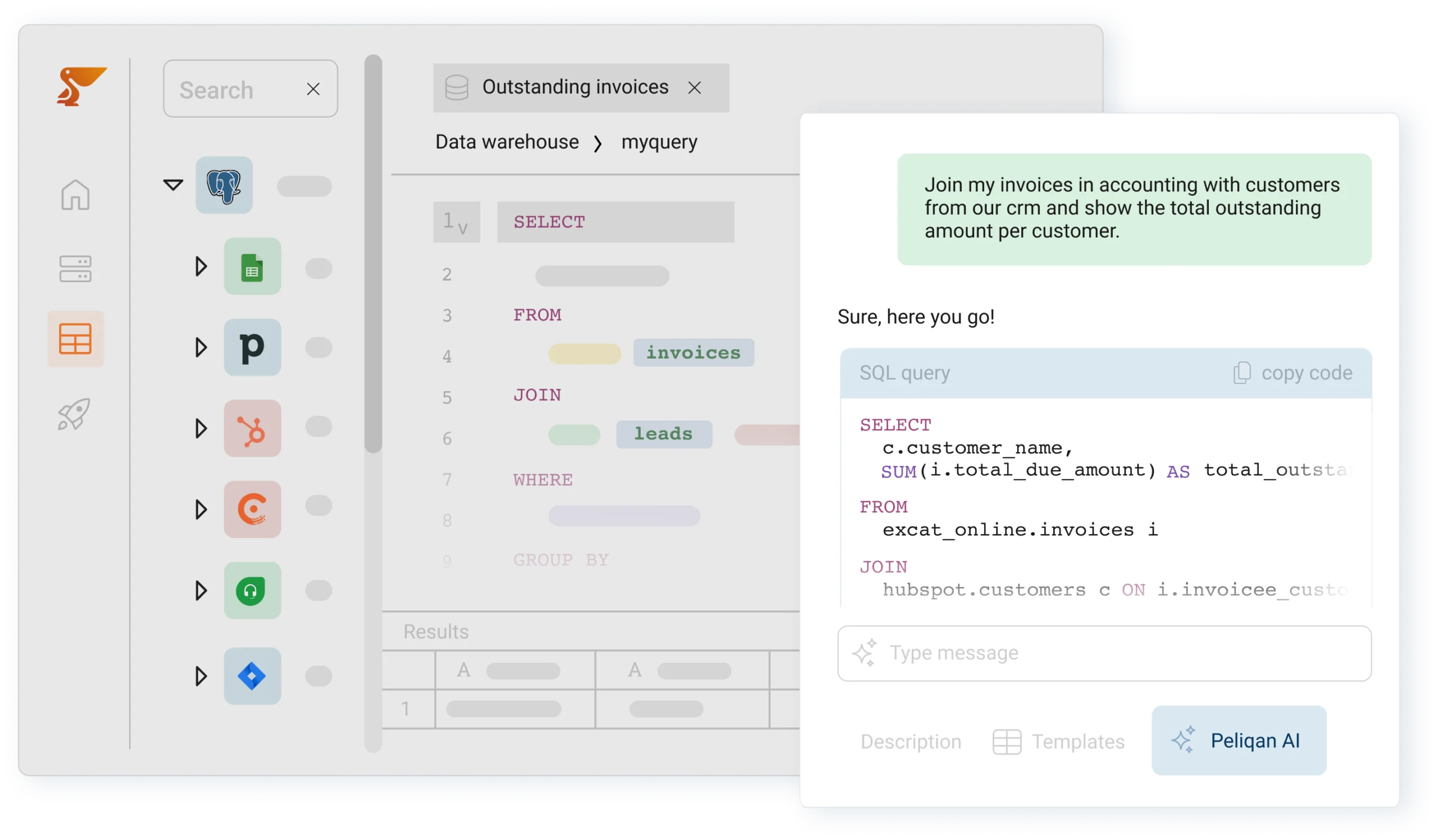
AI assistant
The AI assistant is a built-in chatbot that helps you with writing the correct SQL queries and Python scripts. It uses your active data connections as context to provide the most accurate help. Peliqan’s AI assistant is a virtual data engineer that will save hours of time.
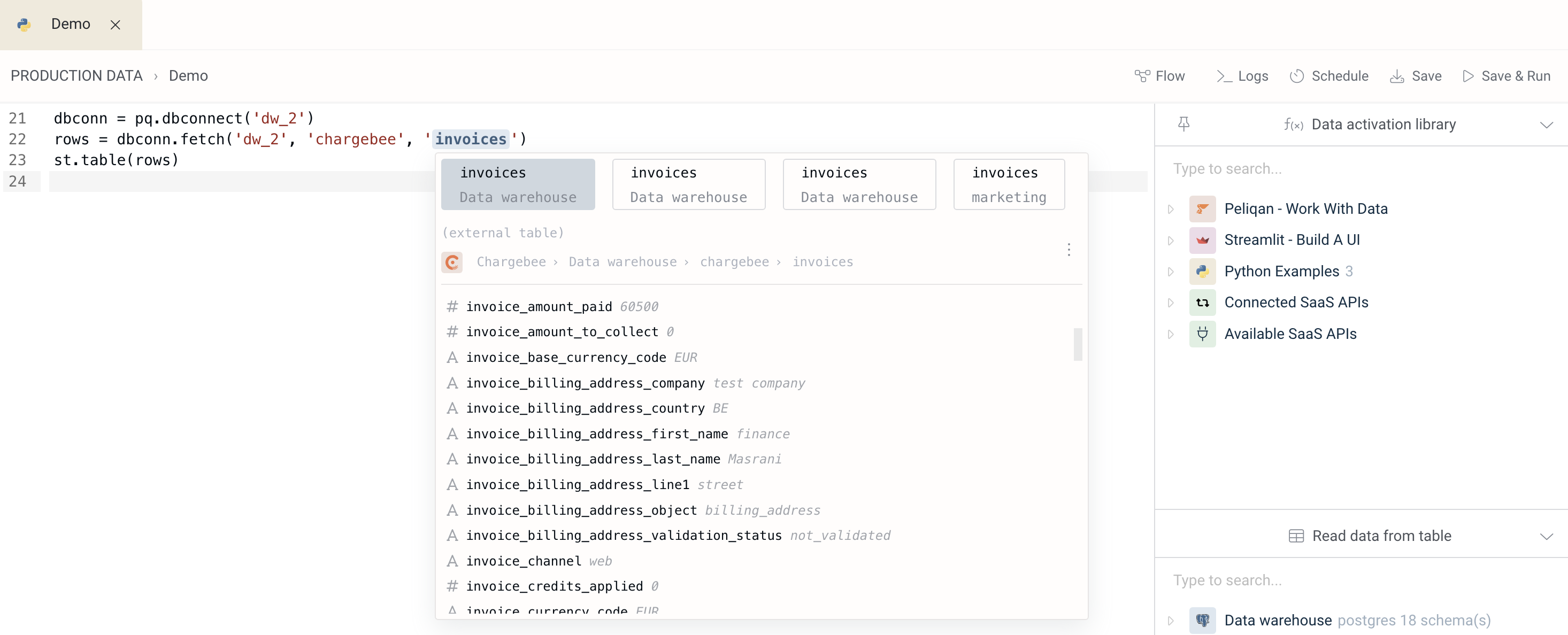
Data previews in the code editor
A unique feature of Peliqan’s code editor is that it shows data previews on hover. For example data tables used in Python code are highlighted and the data structure is shown on hover. This means that you know exactly what to expect when referencing a table or SQL query, even before you run your code.
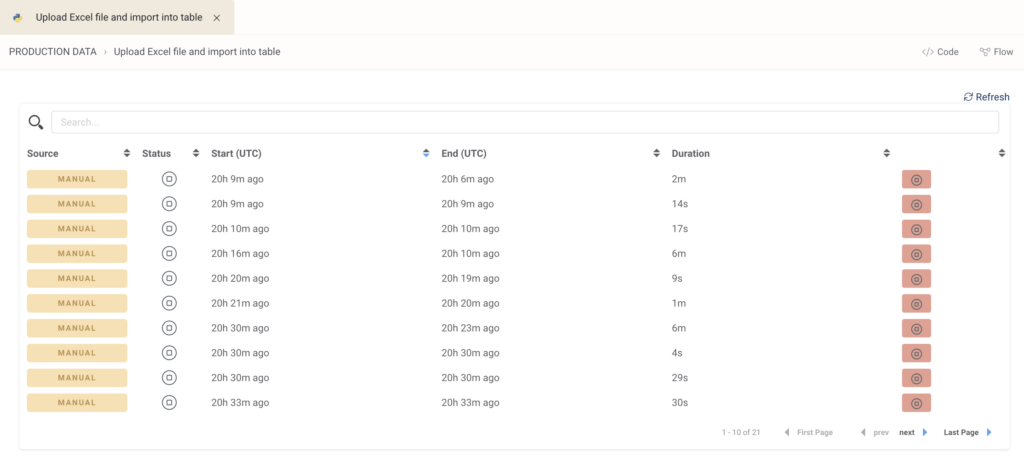
Visibility
Peliqan logs every run of your scripts, both manual runs and scheduled runs. The logs provide visibility into the execution of your code, making it easy to troubleshoot errors and providing maximum visibility on your pipelines, automations and data apps.
Conclusion
Low-code Python is a new paradigm, introduced by Peliqan.io, to empower users that want to implement data integration and data activation solutions efficiently without the need to become a full-fledged data engineer. Low-code Python, combined with SQL, is the cornerstone of the Peliqan.io all-in-one data platform and provides a modern alternative to data platforms that are too complex to use on the one hand, and iPaaS platforms that are not data-centric on the other.




