In today’s data-driven business landscape, organizations rely heavily on insights derived from vast amounts of data collected from various sources. To make sense of this data and use it for informed decision-making, businesses employ data warehousing and ETL (Extract, Transform, Load) processes.
In this comprehensive guide, we’ll dive deep into the world of data warehouse ETL, exploring its components, best practices, and the tools that make it all possible. Whether you’re a data professional looking to optimize your ETL pipeline or a business leader seeking to leverage data for strategic decision-making, this guide has you covered.
Understanding Data Warehouse ETL
What is Data Warehouse ETL?
Data Warehouse ETL is a fundamental process in data integration that involves extracting data from various sources, transforming it into a consistent format, and loading it into a centralized data warehouse. This process forms the backbone of modern business intelligence and analytics initiatives, enabling organizations to make data-driven decisions with confidence.
The ETL Process Explained
Let’s break down the three key stages of the ETL process:
- Extract: In this initial phase, data is collected from multiple sources, which may include relational databases, flat files, APIs, and various applications.
- Transform: The extracted data undergoes a series of operations to clean, standardize, and prepare it for analysis. This may involve data cleansing, deduplication, and applying business rules.
- Load: The final stage involves inserting the transformed data into the target data warehouse, ready for querying and analysis.
The importance of data warehouse ETL lies in its ability to consolidate and standardize data from diverse sources, enabling businesses to gain a holistic view of their operations and make informed decisions.
Data Warehouse ETL Characteristics
While ETL processes are used in various data integration scenarios, data warehouse ETL has some unique characteristics:
- High Volume Data Processing: Data warehouses often deal with massive amounts of historical and current data, requiring robust ETL processes capable of handling high volumes efficiently.
- Complex Transformations: It typically involves more complex transformations to align data from diverse sources with the warehouse’s schema and business rules.
- Incremental Loading: To manage large datasets effectively, it often employs incremental loading techniques, updating only the changed or new data since the last ETL run.
- Dimensional Modeling: ETL processes for data warehouses often need to support dimensional modeling concepts like slowly changing dimensions and fact table updates.
- Historical Data Preservation: Unlike some other ETL scenarios, data warehouse ETL must often preserve historical data for trend analysis and auditing purposes.
Understanding these unique characteristics is crucial for designing and implementing an effective data warehouse ETL solution that meets your organization’s specific needs. To gain a deeper understanding of data warehouse ETL’s unique characteristics, it’s helpful to compare it with other common ETL scenarios.
Data Warehouse ETL Vs Other ETL Types
To better understand the unique position of data warehouse ETL, let’s compare it with other common ETL scenarios:
Feature |
Data Warehouse ETL |
Operational ETL |
Big Data ETL |
|---|---|---|---|
| Data Volume | High | Medium | Very High |
| Data Variety | Structured/Semi-structured | Mostly Structured | Structured/Unstructured |
| Processing Complexity | High | Medium | Very High |
| Historical Data | Preserved | Limited | Often Preserved |
| Transformation Rules | Complex | Moderate | Varied |
| Loading Frequency | Batch/Near Real-time | Real-time/Batch | Streaming/Batch |
| Primary Use Case | Analytics & Reporting | Operational Systems | Advanced Analytics |
To illustrate the real-world impact of data warehouse ETL, let’s examine a hypothetical scenario that demonstrates its transformative power in a business context.
Data Warehouse ETL Example
Let’s consider a hypothetical scenario. Assume a multinational corporation we’ll call GlobalTech, facing challenges that are common in today’s business landscape:
GlobalTech’s finance team was spending weeks each quarter consolidating reports from various regional offices, each using different systems and data formats. The marketing department couldn’t get a clear picture of cross-regional customer behavior, and the supply chain team was making decisions based on outdated information.
Recognizing these challenges, let’s assume GlobalTech implemented a robust data warehouse ETL solution. Here’s how we can envision it unfolding:
- Extraction: The ETL process began by extracting data from multiple sources – CRM systems, ERP databases, flat files from legacy systems, and even semi-structured data from web analytics.
- Transformation: The extracted data underwent complex transformations. Customer IDs were standardized across regions, currencies were converted to a common denomination, and product codes were mapped to a unified catalog.
- Loading: The transformed data was loaded into a centralized data warehouse, structured for optimal querying and analysis.
In this scenario, we can imagine the results were remarkable:
- Financial reporting time was cut from weeks to hours.
- Marketing gained a 360-degree view of customer behavior across all regions.
- The supply chain team could now make decisions based on near real-time data.
- Executive dashboards provided a consistent, up-to-date view of the entire business.
Let’s suppose that within a year, GlobalTech attributed a 15% increase in operational efficiency and a 10% boost in customer retention to their improved data-driven decision-making capabilities, all made possible by their data warehouse ETL implementation.
This success story underscores the transformative potential of well-implemented data warehouse ETL processes. While GlobalTech is an assumed example, the challenges and solutions presented here are based on common scenarios faced by many organizations.
By consolidating and standardizing data from across the organization, companies like our hypothetical GlobalTech can unlock insights that were previously hidden in disparate systems. Whether you’re just starting your data warehouse journey or looking to optimize existing processes, understanding the nuances is key to unlocking the full potential of your organization’s data assets.
Having seen the potential benefits of a well-implemented data warehouse ETL solution, let’s now explore some best practices to ensure your ETL processes are as efficient and effective as possible.
Best Practices for Efficient Data Warehouse ETL
To ensure the success of your data warehouse ETL pipeline, consider the following best practices:

1. Define Clear Data Requirements
Before embarking on the ETL journey, it’s crucial to have a clear understanding of your data requirements. Identify the data sources, the desired format of the transformed data, and the business questions you aim to answer with the data warehouse. This will guide the design and implementation of your ETL process.
2. Ensure Data Quality and Consistency
Data quality is paramount in data warehousing. Implement data validation, cleansing, and standardization techniques during the transformation stage to ensure the accuracy and consistency of the data loaded into the warehouse. Regularly monitor and address any data quality issues to maintain the integrity of your analytics and reporting.
3. Optimize ETL Performance
ETL processes often handle large volumes of data, making performance optimization critical. Implement techniques such as parallel processing, incremental loading, and data partitioning to improve the efficiency of data extraction and loading. Regularly monitor
and tune the ETL pipeline to identify and address performance bottlenecks.
4. Implement Robust Error Handling and Logging
ETL processes are prone to errors and failures due to data inconsistencies, network issues, or system outages. Implement comprehensive error handling and logging mechanisms to quickly identify and resolve issues. Log key metrics such as data volumes, processing times, and error rates to track the health and performance of your ETL pipeline.
5. Ensure Data Security and Compliance
Data security and compliance are critical considerations in data warehousing. Implement appropriate access controls, encryption, and data masking techniques to protect sensitive information. Ensure that your ETL processes comply with relevant data protection regulations such as GDPR, NIS2, or industry-specific standards.
With these best practices in mind, let’s take a look at a powerful tool that can help you implement and manage your data warehouse ETL processes effectively.
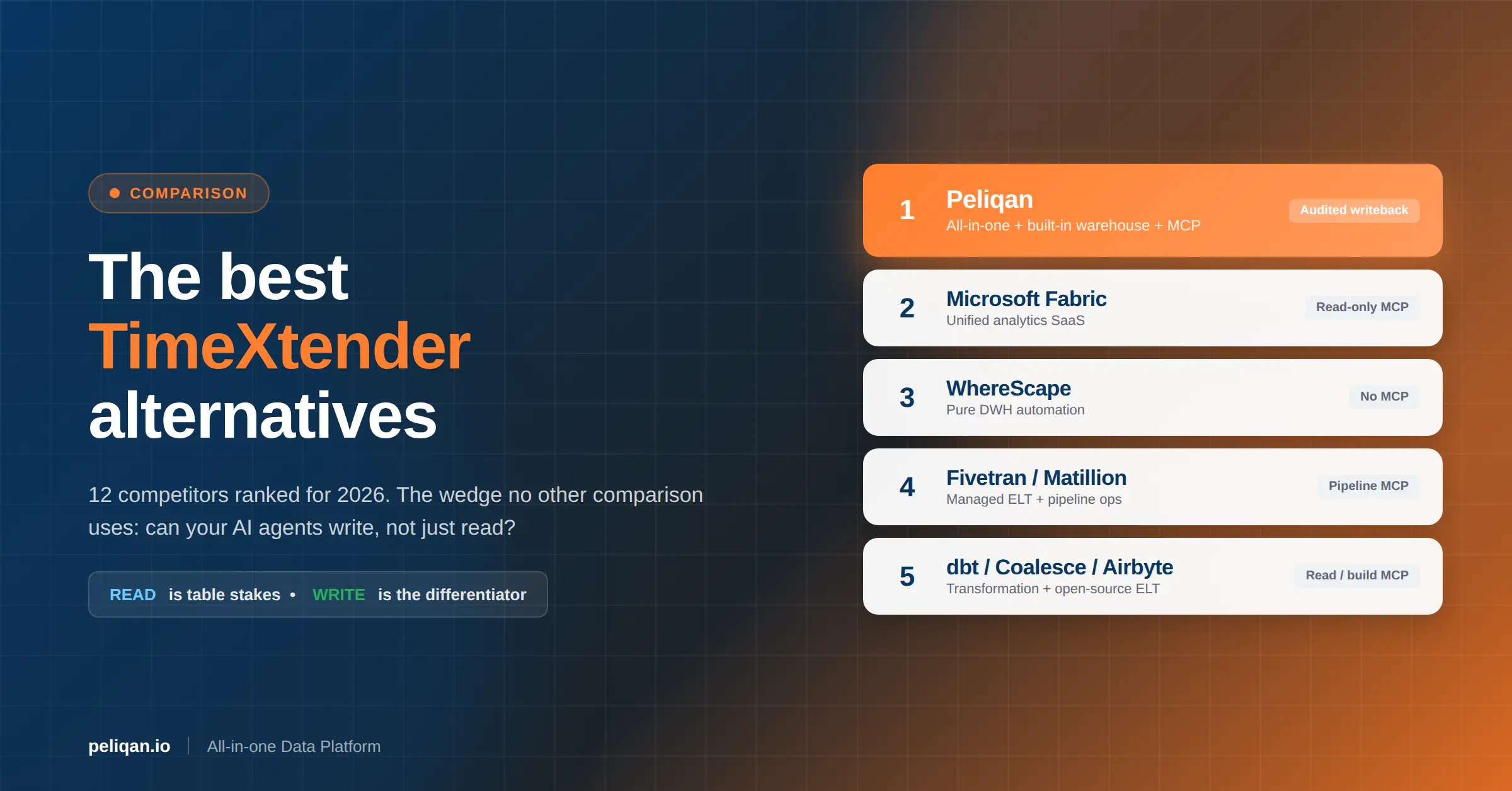
Comparing Top Data Warehouse ETL Tools
Choosing the right ETL tool is crucial for the success of your data warehousing initiative.
| Tool | Key Features | Pros | Cons |
|---|---|---|---|
| Peliqan | – Low-code/no-code ETL – 250+ pre-built connectors – Built-in data warehouse – Python scripting for advanced use cases |
– Built-in data warehouse, data activation, reverse etl – Comprehensive feature set – Flexibility and scalability |
Relatively new player in the market |
| Fivetran | – Automated data pipeline creation – 150+ pre-built connectors – Managed service |
– Fully managed, minimal setup required – Reliable and scalable |
– Limited customization options – Higher pricing for large data volumes |
| Stitch | – Self-service ETL – 100+ pre-built connectors – Integration with popular data warehouses |
– User-friendly interface – Affordable pricing |
– Limited advanced features – Potential performance issues with large datasets |
| Talend | – Comprehensive data integration platform – Supports various data sources and targets – Graphical interface for ETL design |
– Robust feature set – Suitable for complex ETL scenarios |
– Steep learning curve – Higher total cost of ownership |
When selecting an ETL tool, consider factors such as ease of use, scalability, connector availability, and pricing. Tools like Peliqan offer a low-code, user-friendly approach, while platforms like Talend provide advanced features for complex ETL scenarios.
By choosing Peliqan as your ETL and data platform, you can streamline your data warehousing process, empower your team with low-code tools, and unlock valuable insights from your data. Peliqan’s comprehensive feature set, ease of use, and flexibility make it an ideal choice for organizations looking to harness the power of their data without the complexity & overhead of traditional ETL solutions.
Conclusion
Data warehouse ETL is a critical process that enables organizations to harness the power of their data for informed decision-making. By following best practices and selecting the right tools, businesses can build efficient and reliable ETL pipelines that deliver accurate and timely insights.
As the data landscape continues to evolve, staying up-to-date with the latest trends and technologies in data warehousing and ETL is essential. By investing in a robust data warehousing strategy and leveraging the capabilities of modern ETL tools, organizations can unlock the full potential of their data assets and drive business success in the digital age.