






In today’s data-driven world, organizations face the challenge of managing an ever-increasing volume and variety of data. To harness the true power of this information, businesses need efficient ways to collect, process, and analyze data from multiple sources. This is where data orchestration tools come into play.
Data orchestration has become a critical component of modern data strategies, enabling businesses to streamline their data workflows, reduce manual errors, and make data-driven decisions more efficiently. As we move into 2025, the landscape of data orchestration tools continues to evolve, offering more sophisticated features and capabilities than ever before.
In this comprehensive guide, we’ll explore the best data orchestration tools available in 2025, their features, and how they can revolutionize your data management strategies. Whether you’re a data scientist, engineer, or business leader, this guide will help you navigate the complex world of data orchestration and choose the right tool for your organization’s needs.
What is Data Orchestration?
Data orchestration is the process of automating the ingestion, transformation, and movement of data across various systems and storage locations. It involves coordinating complex data workflows to ensure seamless data integration, processing, and analysis of data from disparate sources.
A powerful data orchestration platform ensures that your data workflows are not only automated but also fault-tolerant and scalable. It acts as a central nervous system for data movement – enabling everything from ETL jobs to real-time analytics pipelines. Unlike simple task schedulers, advanced orchestration tools manage dependencies, retries, data lineage, and trigger-based executions.
In a landscape where companies rely heavily on data from both structured and unstructured sources, effective data orchestration ensures accuracy, consistency, and reliability of data across the enterprise ecosystem.
What are Data Orchestration Tools?
Data orchestration tools are essential components of modern data infrastructure. These platforms allow organizations to design, schedule, and monitor complex data workflows across multiple sources and destinations. As data environments become more distributed and real-time, the demand for robust orchestration platforms is rising across industries.
Understanding the key features of data orchestration tools is essential for organizations looking to maximize their data management capabilities. These features not only define the performance of the tools but also determine their alignment with specific business needs:
- Data Integration: A fundamental feature is robust data integration capabilities, allowing seamless connection to diverse data sources, whether they are cloud-based, on-premises, or hybrid. This ensures that data can be compiled from multiple origins into a unified view without silos.
- Workflow Automation: Automation of workflows is crucial for increasing efficiency. This feature enables the automation of data pipelines, orchestrating tasks without the need for continuous human intervention, significantly reducing the risk of manual errors.
- Data Transformation: The ability to transform data on-the-fly is important for making raw data useful. This includes functionalities for cleansing, enriching, and formatting data to meet business requirements.
- Integration with Analytics and BI Tools: Many modern orchestration tools can integrate with business intelligence (BI) platforms, enriching analytical capabilities and enabling organizations to derive actionable insights more effectively.
These features collectively enhance the utility of data orchestration tools, ensuring that organizations can cultivate a data-driven culture that is both efficient and capable of leveraging the full potential of their data assets.
Top 15 Data Orchestration Tools
This section provides a detailed explanation of each of the top data orchestration tools. These summaries will highlight the specific functionalities, strengths, and potential limitations of each tool, assisting organizations in making informed decisions based on their operational needs and strategic objectives.

Here’s a curated list of some of the best data orchestration tools that are widely used by data teams to streamline their workflows, automate processes, and ensure reliability in data operations.
1. Peliqan
 Peliqan is a cutting-edge data orchestration tool designed to streamline complex data workflows with enhanced usability. Its robust low-code interface allows users to design, deploy, and manage data pipelines efficiently. Peliqan focuses on simplifying the orchestration process without sacrificing functionality, positioning itself as an agile solution for modern data challenges.
Peliqan is a cutting-edge data orchestration tool designed to streamline complex data workflows with enhanced usability. Its robust low-code interface allows users to design, deploy, and manage data pipelines efficiently. Peliqan focuses on simplifying the orchestration process without sacrificing functionality, positioning itself as an agile solution for modern data challenges.
Key Features:
- Advanced data activation and reverse ETL functionalities: These features empower organizations to not only extract and transform data but also to activate it across various platforms, ensuring timely access to insights.
- Comprehensive support for a diverse range of data sources: Whether it’s structured or unstructured data, our solution connects with multiple sources, simplifying data ingestion and enhancing analytics capabilities.
- Real-time data monitoring with robust alerting: Stay ahead of potential issues with continuous monitoring and customizable alerts that keep you informed of any anomalies or performance drops.
- Scalable architecture for data warehousing: Our architecture adapts to your growing data needs, allowing for seamless scaling without compromising performance or efficiency.
- Seamless integration with machine learning models: Effortlessly incorporate machine learning into your workflows, enabling predictive analytics and smarter decision-making based on real-time data.
Limitations:
- Peliqan is not a full fledged BI tool, you still need Metabase, Power BI or similar tools
2. Apache Airflow

Apache Airflow is an open-source platform designed to programmatically author, schedule, and monitor workflows. It allows complex data processing pipelines to be defined through Python code, enabling dynamic, scalable, and extensible workflow management. The orchestrator has a robust ecosystem and community support, ideal for organizations with in-house technical expertise.
Key Features:
- Built-in support for various task execution strategies
- Dynamic pipeline generation
- Rich user interface for monitoring
- Extensive plugin support
- Highly configurable
Limitations:
- Steeper learning curve can present challenges for teams lacking experience with its framework
3. Dagster

Dagster is an open-source data orchestration platform that emphasizes the development, testing, and deployment of data pipelines with high reliability and observability. It is designed to empower data teams to build production-grade data applications by focusing on software engineering best practices such as modularity, type safety, and testability. Dagster’s design promotes strong developer ergonomics and data pipeline governance, making it ideal for teams that value both agility and control.
Key Features:
- Type-aware pipelines and solid typing support
- Declarative configuration and pipeline reusability
- Integrated development tools (Dagit UI)
- Built-in testing and versioning support
- Seamless integration with modern data stack
Limitations:
- Relatively newer ecosystem: While rapidly growing, Dagster’s ecosystem is still smaller compared to more established tools like Airflow, potentially limiting plugin availability or community support in niche use cases.
4. AWS Step Functions
AWS Step Functions is a serverless orchestration service that enables developers to coordinate microservices and manage distributed applications seamlessly. By using state machines, it helps visualize application workflows, making troubleshooting and monitoring straightforward. This tool is ideal for users deeply integrated into the AWS ecosystem, facilitating the building of robust applications with minimal administrative overhead.
Key Features:
- Serverless architecture
- Workflow visualization
- Integration with AWS services
- Supports long-running processes
- Built-in error handling
Limitations:
- Vendor lock-in might limit flexibility, and complexity in setup can deter agile project implementations
5. Talend
Talend offers a comprehensive suite of cloud-based and on-premises data integration tools. Its data orchestration capabilities allow organizations to automate their data workflows, ensuring quality data is delivered across systems. Talend is particularly valuable for enterprises needing robust ETL processes and seamless integration across hybrid environments.
Key Features:
- Data quality management
- Cloud and on-premises integration
- Extensive pre-built connectors
- Code-free data preparation
- Collaboration tools for teams
Limitations:
- The pricing model for enterprise features can be high, possibly making it less accessible for smaller organisations
6. Metaflow
 Metaflow is a human-centric data science framework developed by Netflix to manage real-life data science workflows. It simplifies the process of building and managing machine learning models, focusing on usability for data scientists and ensuring that they can iterate rapidly. Metaflow abstracts away the complexities of infrastructure, enabling users to concentrate on their data and algorithms while providing tools for version control, resource management, and deployment.
Metaflow is a human-centric data science framework developed by Netflix to manage real-life data science workflows. It simplifies the process of building and managing machine learning models, focusing on usability for data scientists and ensuring that they can iterate rapidly. Metaflow abstracts away the complexities of infrastructure, enabling users to concentrate on their data and algorithms while providing tools for version control, resource management, and deployment.
Key Features:
- User-friendly API for workflow definitions
- Integrated data versioning and lineage tracking
- Compatibility with cloud services like AWS
- Automatic resource scaling for compute-intensive tasks
- Support for local development and easy deployment
Limitations:
Reliance on AWS for execution can create challenges for organizations
7. Luigi

Luigi is a open-source Python package that helps build complex data pipelines in a simple way. Developed by Spotify, it focuses on dependency resolution and visual representation of execution, streamlining the workflow orchestration process. It’s ideal for managing long-running batch jobs with complex interdependencies.
Key Features:
- Dependency tracking
- Visual representation of task workflows
- Easy integration with existing Python code
- Built-in scheduling capabilities
- Extensible task creation
Limitations:
- Its code-centric nature and limited user interface can make it less friendly for non-technical users
8. Informatica
Informatica offers an enterprise-grade data management platform that encompasses data integration, data quality, and data governance features. Its orchestration capabilities allow organizations to automate workflows across diverse data environments, providing a comprehensive solution for data-driven enterprises.
Key Features:
- Extensive data integration capabilities
- Advanced data quality features
- Real-time processing and analytics
- Collaboration and workflow management
- Scalable architecture for high volumes
Limitations:
- High costs and complexity might be prohibitive for smaller setups or less resourceful organizations
9. Apache NiFi

Apache NiFi is a robust data integration and orchestration tool that supports data flow automation between systems. It provides a web-based user interface for designing and monitoring data flows, which can range from simple to complex. NiFi is particularly effective in scenarios requiring real-time data ingestion and transformation, offering users complete control over the flow of data between heterogeneous systems.
Key Features:
- Real-time data ingestion and transformation
- Visual flow design
- Provenance tracking for data lineage
- Extensible architecture with numerous processors
- Fine-grained security and access control
Limitations:
- The complexity of configuration can overwhelm new users, necessitating additional training resources
10. Kubernetes

Kubernetes is an open-source platform for automating the deployment, scaling, and operations of application containers. Though primarily a container orchestration system, its capabilities allow data orchestration workflows to be implemented at scale, particularly for microservices architectures.
Key Features:
- Automated scaling and management
- Strong community and ecosystem
- Service discovery
- Rolling updates and rollbacks
- Resource management capabilities
Limitations:
- A strong requirement for DevOps knowledge might alienate teams without robust technical expertise
11. Data Build Tool (dbt)

dbt (data build tool) is a command-line tool that enables data analysts and engineers to transform data in their warehouse more effectively. It facilitates data transformations through SQL-based models while empowering teams to maintain and document their analytic workflows systematically. dbt stands out for its capabilities in testing, version control, and dependency management, making it a preferred choice for analytics engineering.
Key Features:
- SQL-based data transformations
- Version control for transformations
- Built-in testing and documentation
- Integration with popular data warehouses
- Strong community-driven support
Limitations:
- While focused more on analytics engineering, it may not fulfil all orchestration needs independently
12. Matillion
Matillion is a cloud-native ETL tool designed for data integration and transformation processes. It provides an intuitive interface specifically built for data transformation in cloud environments.
Key Features:
- Intuitive drag-and-drop interface
- Advanced data transformation capabilities
- Real-time data loading and orchestration
- Rich library of pre-built connectors for various data sources
- Seamless integration with cloud data warehousing solutions
Limitations:
- High costs associated with its subscription model may deter smaller operations looking for cost-effective solutions
13. Fivetran
 Fivetran is a data integration platform that automates the ETL (Extract, Transform, Load) process, enabling seamless data ingestion from various sources into data warehouses. Its fully managed connector approach allows users to consolidate data without the need for technical expertise, ensuring that analytics teams can access high-quality, up-to-date data with minimal overhead. Fivetran’s connectors automatically adjust to schema changes, providing a resilient and adaptive data pipeline solution.
Fivetran is a data integration platform that automates the ETL (Extract, Transform, Load) process, enabling seamless data ingestion from various sources into data warehouses. Its fully managed connector approach allows users to consolidate data without the need for technical expertise, ensuring that analytics teams can access high-quality, up-to-date data with minimal overhead. Fivetran’s connectors automatically adjust to schema changes, providing a resilient and adaptive data pipeline solution.
Key Features:
- Automated data replication
- Schema drift handling
- Pre-built connectors for numerous data sources
- Real-time data syncing
- Built-in data transformation capabilities
Limitations:
- Limited control over data transformation processes may restrict data customisation and processing needs
14. Airbyte
 Airbyte is an open-source data integration platform designed to facilitate the extraction and loading of data from various sources to data destinations. Its modular architecture allows for customizable connectors, which can be developed or modified by users to suit their specific needs. Airbyte focuses on providing flexibility and transparency to its users while maintaining the ability to handle high volume data transfers efficiently.
Airbyte is an open-source data integration platform designed to facilitate the extraction and loading of data from various sources to data destinations. Its modular architecture allows for customizable connectors, which can be developed or modified by users to suit their specific needs. Airbyte focuses on providing flexibility and transparency to its users while maintaining the ability to handle high volume data transfers efficiently.
Key Features:
- Open-source and extensible connectors
- Centralised configuration dashboard
- Incremental data sync options
- High-level monitoring and logging features
- Community-driven improvements
Limitations:
- Being relatively new, it may not have a mature ecosystem, potentially leading to volatility and support issues
15. Databricks Workflow
 Databricks Workflow is an orchestration feature within the Databricks unified analytics platform that provides data scientists and engineers with a way to automate data processing workflows and manage machine learning pipelines efficiently. It integrates seamlessly with Apache Spark, allowing for distributed data processing at scale. Databricks Workflow emphasizes collaboration by enabling various teams to engage in the same workspace, facilitating version control and reproducibility of data insights.
Databricks Workflow is an orchestration feature within the Databricks unified analytics platform that provides data scientists and engineers with a way to automate data processing workflows and manage machine learning pipelines efficiently. It integrates seamlessly with Apache Spark, allowing for distributed data processing at scale. Databricks Workflow emphasizes collaboration by enabling various teams to engage in the same workspace, facilitating version control and reproducibility of data insights.
Key Features:
- Integration with Apache Spark for scalable processing
- Job scheduling and monitoring capabilities
- Support for multiple programming languages (Python, R, SQL, Scala)
- Direct integration with Delta Lake
- Collaborative workspace for teams
Limitations:
- Its pricing model based on compute resources can become costly, especially under heavy workloads
This extensive collection of tools outlines the diverse landscape of data orchestration platforms available today, each with unique strengths and considerations, enabling organizations to choose the optimal solution tailored to their specific data management and integration needs.
16. Orchestra
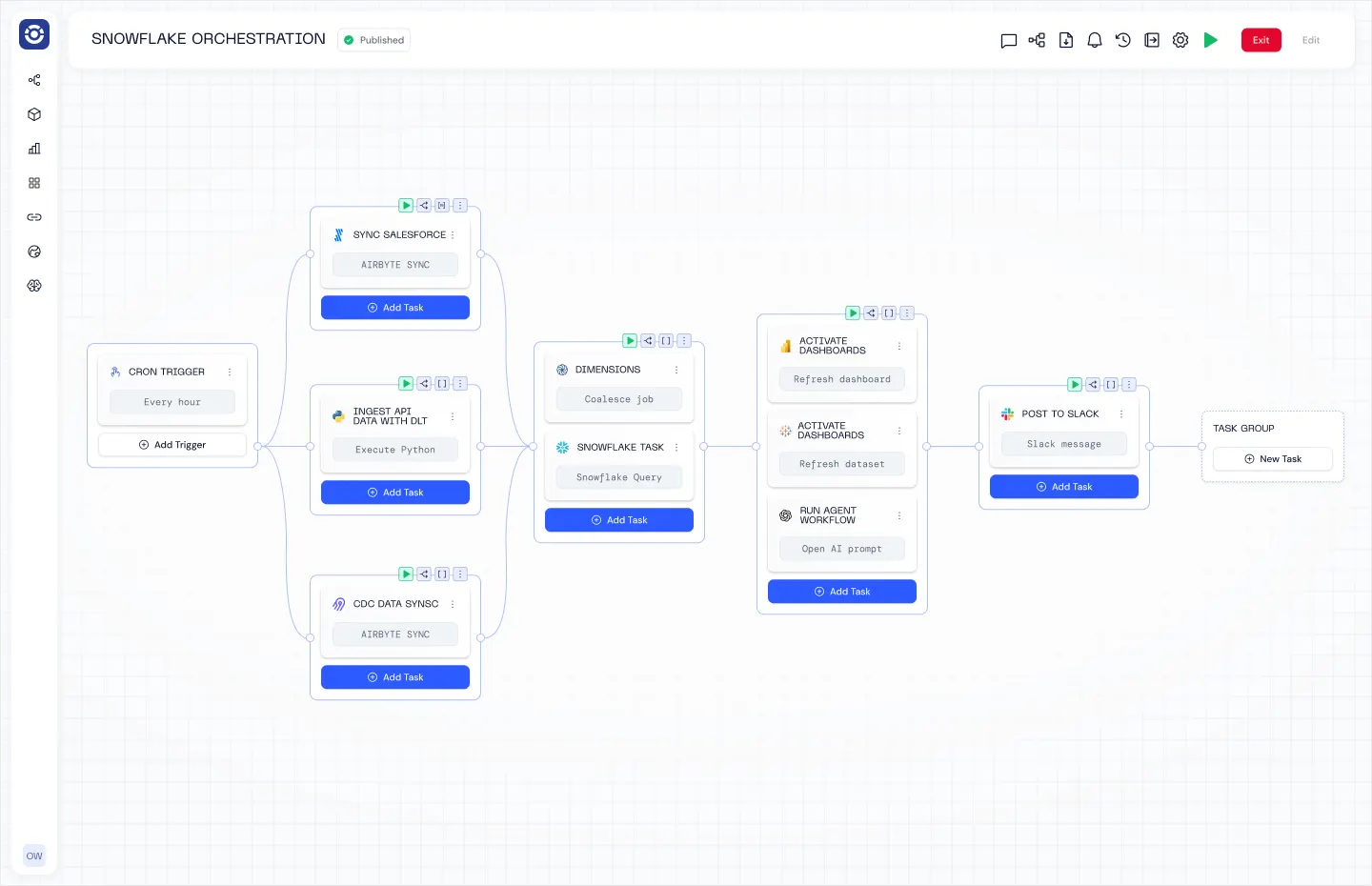
Orchestra is a declarative orchestration platform that operates as a single pane of glass. It is by far the easiest way to build Data and AI Workflows, and operates as a sort of “data person first” hybrid between an incredibly advanced Apache Airflow set-up and n8n.
Enterprises and Scaling data teams Orchestra for its ease of use, speed to live, and low barrier to entry. With Orchestra teams can implement in days not months, spend less time managing and debugging pipelines, and can enable better self-serve patterns that allow them to work on platform not in it.
Key Features
- Declarative Orchestration using either GUI or .yml makes building pipelines 90% faster
- Integrated alerting, data quality monitoring and dashboarding removes need for additional observability tools (reduce TCO by 80%)
- dbt is a first-class citizen, with advanced features like cost monitoring and state-aware orchestration out of the box
- Tons of enterprise features like workspaces, RBAC, hybrid deployment
- An auto-updating data catalog (see their latest product update here)
Limitations
- Fully Cloud based so not a fit for fully on-premise setups
Data Orchestration Tools Comparison
In order to make informed decisions regarding data orchestration tools, it is essential to conduct a thorough comparison of the top data orchestration platforms available in the market.
The following table presents a detailed overview of key features, strengths, and considerations for each tool, enabling organizations to evaluate which orchestration platform best aligns with their specific operational requirements and strategic goals.
This comparison table provides a comprehensive overview of the top data orchestration tools, highlighting their open-source status, advantages, disadvantages, and pricing structures. Organizations should carefully weigh these factors against their unique requirements and operational environments when selecting an orchestration solution.
Selecting the Ideal Data Orchestration Tool
Choosing the most suitable data orchestration tool involves several critical considerations that align with an organization’s technical requirements, team capabilities, and overall data strategy. Below is a table that summarises the essential factors to evaluate when making this decision:
With recent advancements in data orchestration, Peliqan stands out as a great tool, offering some fantastic benefits:
- Dynamic Data Lineage Tracking: Peliqan provides real-time visibility into data flow and transformations, making it easier for users to trace data origin and ensure compliance with governance standards.
- User-Friendly Interface with Low-Code Capabilities: Peliqan’s intuitive low-code interface allows users to design data workflows without extensive coding knowledge, accommodating a wider range of users and reducing the barriers to entry.
- Seamless Integration Across Various Environments: Peliqan supports effortless connectivity with on-premise, cloud, and hybrid environments, ensuring compatibility with a wide range of data sources and services.
- Customizable Alerting and Monitoring Systems: The tool features robust monitoring capabilities that notify users of performance anomalies or workflow failures, allowing for swift corrective actions while maintaining data integrity.
These unique features position Peliqan as a leading contender in the data orchestration landscape, providing organizations with the tools necessary to optimize their data management strategies while ensuring compliance and operational efficiency.
Conclusion
In summary, the modern landscape of data orchestration tools presents a variety of choices, each catering to different organizational needs and operational frameworks.
Among these, Peliqan stands out as an exceptional solution that not only addresses the complexities of data management but does so with a focus on usability, integration, and compliance.
Its streamlined workflows and user-friendly interface significantly reduce the barriers to creating and maintaining efficient data pipelines, while robust integration capabilities ensure that it can adapt to a myriad of existing infrastructures.
Moreover, the built-in monitoring tools provided by Peliqan empower organisations to uphold data quality and compliance standards, a crucial factor in today’s data-driven environment. As businesses increasingly depend on effective data orchestration to drive insights and decision-making, Peliqan’s thoughtful design and comprehensive functionality make it a superior choice for teams aiming to harness the full potential of their data assets.





