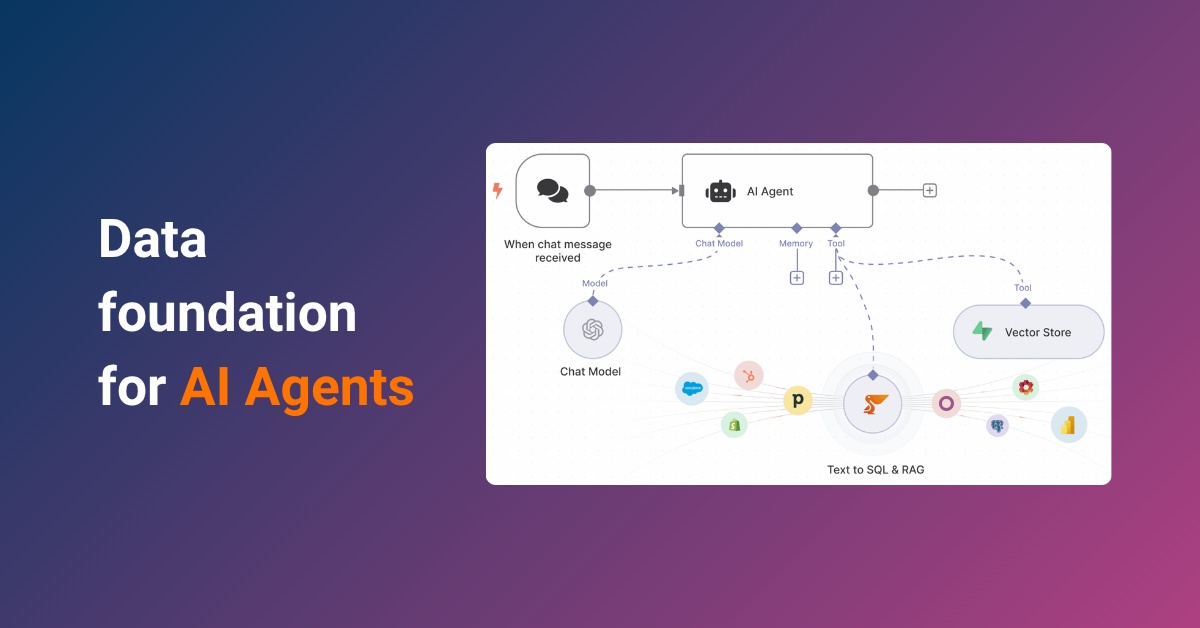








Python has become the “de facto” language for ETL (Extract, Transform, Load) workflows due to its simplicity and rich ecosystem of libraries.
However, managing end-to-end data pipelines with raw Python often requires stitching together multiple tools, writing repetitive code, and relying on data engineering expertise. Peliqan.io redefines Python ETL by combining low-code flexibility, built-in infrastructure, and AI-powered automation into a single platform.
Why Python ETL? Key Challenges & How Peliqan Solves Them
Traditional Python ETL workflows face common hurdles:
- Complex Setup: Connecting data sources, orchestrating pipelines, and maintaining infrastructure demands engineering resources.
- Tool Fragmentation: Teams juggle separate tools for ingestion (Airbyte), transformations (dbt), reverse ETL (Census), and BI (Metabase).
- Limited Scalability: Scripts that work for small datasets often fail under heavy loads or complex transformations.
Peliqan.io simplifies Python ETL by providing:
- A low-code UI for connecting 250+ data sources (SaaS apps, databases, files)
- Built-in data warehouse (or connect Snowflake/BigQuery)
- Low-code Python scripting for transformations, ML, and data activation
- One-click deployment of tools like Metabase, Airflow, and Reverse ETL pipelines
Peliqan vs. Traditional Python ETL Tools: A Comparison
Python ETL Tools: Best Practices & Integration
Modern ETL projects often combine the best-of-breed tools to handle different pipeline stages. However, integrating these can be complex:
- Modular Design: Use specialized tools for extraction (e.g., Airbyte) and transformation (e.g., Apache Airflow) but be aware of the overhead.
- Unified Interfaces: A low-code platform like Peliqan.io eliminates integration challenges by providing one interface for the entire ETL process.
- Automation & Monitoring: Incorporate AI-driven automation to reduce manual intervention and improve pipeline reliability.
Peliqan.io’s integrated approach simplifies these best practices by automating orchestration, error handling, and scaling—allowing teams to focus on insights rather than infrastructure.
Modern Python ETL Tools: A Comparison
A comprehensive analysis of current ETL tools in the Python ecosystem, examining their strengths, weaknesses, and features to help teams make informed decisions about their data infrastructure.
Build End-to-End Python ETL Pipelines in 4 Steps
A practical guide to implementing complete ETL solutions using Peliqan’s platform, breaking down the process into manageable steps while highlighting key features and capabilities at each stage.
Step 1: Extract Data from Any Source
Connect to databases (PostgreSQL, MySQL), SaaS apps (Salesforce, HubSpot), cloud storage (S3, Google Drive), or APIs in minutes. Peliqan auto-generates ETL pipelines with schema detection and incremental syncs.
Python Tip: Use Peliqan’s pq.connect() method to access any dataset directly in your scripts:
# Query Salesforce data without writing API code
salesforce_data = pq.connect(“salesforce”).query(“SELECT * FROM leads”)
Step 2: Transform with Low-Code Python & SQL
Combine spreadsheet-style edits, SQL models, and Python scripts in a single interface:
- Spreadsheet UI: Business users can filter, add columns, and apply Excel-like formulas.
- SQL Models: Reusable transformations with dependency tracking.
- Python Scripts: Leverage pandas, NumPy, or custom libraries in 10x less code.
# Calculate customer LTV with pandas, sourced from BigQuery
@pq.transform(output_table=”customer_ltv”)
def calculate_ltv():
orders = pq.bigquery.query(“SELECT * FROM orders”)
ltv = orders.groupby(‘customer_id’)[‘revenue’].sum()
return ltv
Step 3: Load to Your Data Warehouse
Choose Peliqan’s built-in warehouse (scales to TBs) or sync transformed data to Snowflake/BigQuery. Automatically optimize tables for analytics with partitioning and indexing.
Step 4: Activate Data with Reverse ETL & APIs
Activate your data. Push insights back to operational tools (e.g., Salesforce, HubSpot) using:
- No-Code Syncs: Map fields visually for 1-way or 2-way syncs.
- Python Writebacks: Add custom logic (e.g., lead scoring) before syncing
# Send high-value leads to Salesforce
high_value_leads = pq.sql(“SELECT * FROM customer_ltv WHERE ltv > 10000”)
pq.salesforce.update(“Lead”, high_value_leads)
Advanced Python ETL Capabilities
A suite of advanced features that enhance the ETL process with artificial intelligence, real-time processing, and enterprise-grade governance tools, providing additional value beyond basic ETL functionality.
AI-Assisted Development
- Peliqan’s AI assistant helps you to write SQL queries to get to insights fast.
- Ask your question in plain English and immediately see the result in Peliqan’s rich spreadsheet viewer.
Real-Time Data Apps & APIs
- Publish APIs: Expose ETL outputs as REST endpoints in one click.
- Webhooks: Trigger Python scripts from external events (e.g., Stripe payment).
Enterprise-Grade Governance
- Data Lineage: Track column-level lineage across SQL, Python, and spreadsheets.
- Data Catalog: Annotate datasets and enforce access controls.
When to Choose Peliqan Over Pure Python ETL Tools
Clear guidance on scenarios where Peliqan’s integrated platform offers advantages over traditional Python ETL approaches, helping teams make informed decisions about their data infrastructure.
Peliqan.io is ideal for teams that need:
- Speed: Go from raw data to production pipelines in hours, not weeks.
- Collaboration: Let analysts use SQL/spreadsheets while developers script in Python.
- Cost Efficiency: Eliminate the overhead of managing Airflow, dbt, and separate ETL tools.
Get Started with Python ETL on Peliqan.io
- Free Trial: Start with 14 days (no credit card required).
- Template Library: Deploy pre-built ETL pipelines (e.g., Shopify to BigQuery).
- Support: Access documentation tailored for Python developers.