




ETL vs ELT – this is one of the most critical decisions data teams face when building modern data infrastructure. As organizations generate more data than ever before, choosing the right approach to extract, transform, and load that data can mean the difference between agile, insight-driven operations and costly, sluggish data pipelines.
In this comprehensive guide, we’ll break down everything you need to know about ETL vs ELT: how each process works, their key differences, when to use each approach, and how modern data platforms are blending both methodologies for optimal results.
What is ETL? Understanding Extract, Transform, Load
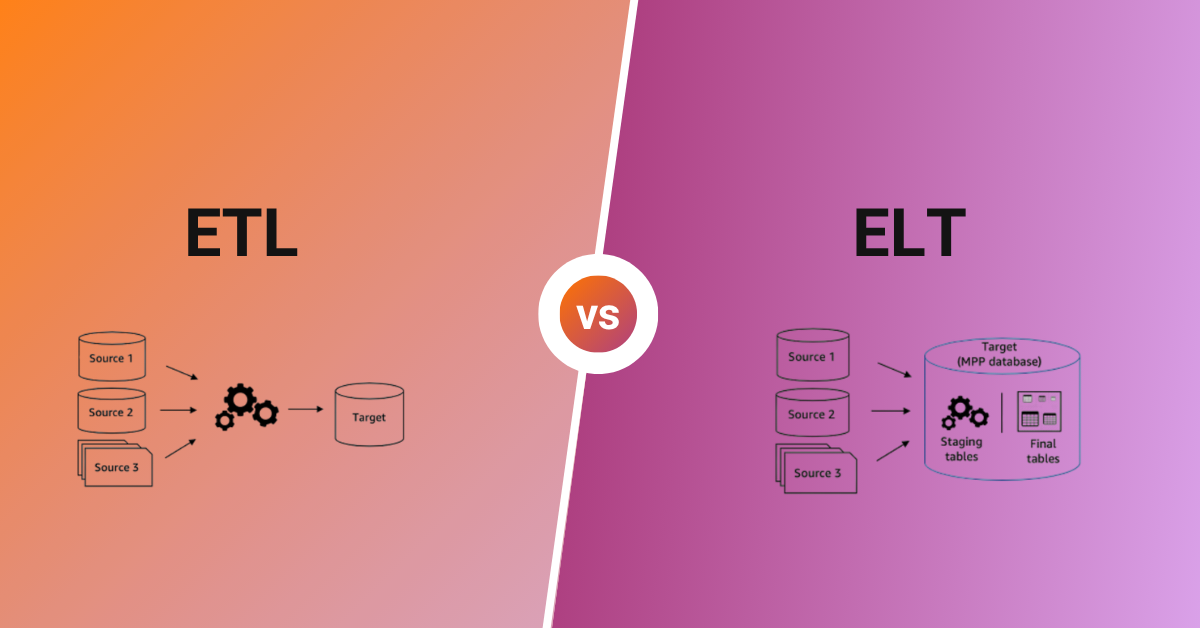
ETL stands for Extract, Transform, Load—a traditional data integration methodology that has been the backbone of business intelligence and data warehousing for decades. In the ETL process, data moves through three distinct stages in a specific order.
How ETL Works: Step-by-Step
1. Extract: Data is pulled from multiple source systems, including databases, CRM platforms, ERP systems, flat files, and APIs. This data is temporarily stored in a staging area.
2. Transform: Before loading into the target system, data undergoes transformation on a dedicated ETL server or middleware platform. Transformations include data cleansing, deduplication, standardization, aggregation, joining datasets, applying business rules, and converting data types to match the target schema.
3. Load: The cleaned and transformed data is loaded into the destination data warehouse, where it’s ready for analysis and reporting.
ETL Example in Practice
Consider a retail company that collects sales data from multiple stores and wants to consolidate information into a centralized data warehouse for analysis:
- Extract: Point-of-sale transaction data, e-commerce orders, inventory levels, and customer information are extracted from disparate systems and stored in a staging environment.
- Transform: The ETL tool standardizes date formats, converts currencies, removes duplicate customer records, calculates sales totals, and applies regional tax rules—all before loading.
- Load: Clean, analysis-ready data is loaded into the data warehouse with a predefined schema optimized for business intelligence queries.
Advantages of ETL
- Data quality assurance: Only clean, validated data enters your warehouse, ensuring high data quality from the start.
- Compliance-friendly: Sensitive data can be masked, encrypted, or removed before it reaches the target system.
- Mature ecosystem: Decades of development have produced robust, well-documented ETL tools with extensive community support.
- Predictable storage costs: Since only transformed data is stored, you have better control over storage requirements.
- Reduced warehouse load: Heavy transformations happen outside the warehouse, preserving compute resources for analytics.
Disadvantages of ETL
- Slower time-to-insight: Data must complete transformation before becoming available for analysis.
- Infrastructure overhead: Requires dedicated servers and resources for transformation processing.
- Limited flexibility: Changing transformation logic often requires rebuilding pipelines from scratch.
- Raw data loss: Once transformed, original source data may no longer be accessible for re-analysis.
- Scalability bottlenecks: The transformation layer can become a chokepoint as data volumes grow.
What is ELT? Understanding Extract, Load, Transform
ELT stands for Extract, Load, Transform—a modern data integration approach that reverses the traditional ETL sequence. In ELT, raw data is loaded directly into the target system first, and transformations happen within the data warehouse or data lake using its native processing power.
How ELT Works: Step-by-Step
1. Extract: Data is extracted from source systems, similar to ETL.
2. Load: Raw, untransformed data is loaded directly into the target system—typically a cloud data warehouse like Snowflake, BigQuery, or Amazon Redshift.
3. Transform: Transformations are performed within the data warehouse using SQL, Python, or dedicated transformation tools like dbt. The warehouse’s compute power handles all data manipulation.
ELT Example in Practice
Consider a healthcare organization collecting patient data from electronic health records, medical devices, and insurance claims:
- Extract: Raw data from all sources is extracted via APIs and connectors.
- Load: All data—in its original format—is loaded into staging tables within a cloud data warehouse, preserving the complete dataset.
- Transform: Data engineers and analysts write SQL transformations directly in the warehouse to cleanse records, normalize patient identifiers, aggregate treatment outcomes, and build analytical models.
Advantages of ELT
- Faster data availability: Raw data is immediately accessible for exploration and ad-hoc analysis.
- Superior scalability: Cloud data warehouses can handle massive transformation workloads by scaling compute on demand.
- Flexibility and agility: Transformation logic can be modified without rebuilding extraction pipelines.
- Full data preservation: Raw data remains available for future re-analysis or new use cases.
- Simplified architecture: No need for separate transformation servers—the warehouse handles everything.
- Better for real-time analytics: Data lands faster, supporting near-real-time dashboards and alerts.
Disadvantages of ELT
- Higher storage costs: Storing raw data alongside transformed data increases storage requirements.
- Compliance complexity: Sensitive raw data in the warehouse requires robust access controls and governance.
- Potential data quality issues: Without pre-load validation, bad data can enter your analytical systems.
- Warehouse compute costs: Heavy transformations consume warehouse resources, potentially increasing costs.
- Risk of data swamps: Without proper governance, raw data lakes can become unmanageable.
ETL vs ELT: Key Differences Explained
Understanding the core differences between ETL and ELT is essential for choosing the right approach for your organization. Let’s examine these differences across critical dimensions.
1. Transformation Timing and Location
The most fundamental difference in the ETL vs ELT debate is when and where transformations occur.
- ETL: Transformations happen before loading, in a dedicated staging environment or ETL server. Only processed data reaches your warehouse.
- ELT: Transformations happen after loading, inside the data warehouse itself. Raw data is stored first, then transformed on-demand.
2. Data Storage Philosophy
- ETL: Follows a “transform-then-store” philosophy. Only curated, schema-compliant data is retained, which can limit future analytical flexibility.
- ELT: Follows a “store-then-transform” philosophy. All raw data is preserved, enabling analysts to create new transformations and derive insights from historical data.
3. Scalability and Performance
- ETL: Scalability is constrained by the transformation layer’s capacity. As data volumes grow, ETL servers can become bottlenecks requiring expensive upgrades.
- ELT: Leverages the elastic scalability of cloud data warehouses. Compute resources scale automatically to handle growing data volumes and complex transformations.
4. Infrastructure and Cost Structure
- ETL: Higher upfront infrastructure costs for transformation servers, but potentially lower long-term storage costs since only transformed data is retained.
- ELT: Lower infrastructure costs (no separate transformation layer), but potentially higher storage and compute costs over time.
5. Data Accessibility and Flexibility
- ETL: Analysts only access transformed data, limiting exploratory analysis. Changing requirements may require pipeline modifications.
- ELT: Full raw data access enables ad-hoc queries, data exploration, and the ability to answer questions that weren’t anticipated when pipelines were built.
6. Compliance and Data Governance
- ETL: Easier to implement data privacy and security controls since sensitive data can be scrubbed or masked before entering the warehouse.
- ELT: Requires more sophisticated governance frameworks to protect sensitive raw data within the warehouse, including role-based access control and dynamic data masking.
7. Real-Time Capabilities
- ETL: The transformation step introduces latency, making ETL less suitable for real-time or streaming data use cases.
- ELT: Raw data lands quickly, making ELT better suited for real-time analytics, streaming data, and time-sensitive business decisions.
ETL vs ELT Comparison Table
| Criteria | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| Process Order | Extract → Transform → Load | Extract → Load → Transform |
| Transformation Location | Separate staging area/ETL server | Inside the data warehouse |
| Data Stored | Only transformed data | Raw and transformed data |
| Scalability | Limited by transformation infrastructure | Highly scalable via cloud compute |
| Time-to-Insight | Slower (transformation delays) | Faster (immediate data availability) |
| Flexibility | Less flexible; predefined transformations | Highly flexible; ad-hoc transformations |
| Infrastructure Costs | Higher upfront (transformation servers) | Lower upfront (no separate layer) |
| Storage Costs | Lower (only transformed data) | Higher (raw data retention) |
| Data Quality Control | Strong pre-load validation | Requires in-warehouse quality checks |
| Compliance | Easier to implement | Requires additional governance |
| Best For | Legacy systems, strict compliance, complex predefined transforms | Big data, cloud warehouses, real-time analytics, data exploration |
| Skill Requirements | Traditional ETL tool expertise | SQL, cloud platform, modern tooling |
| Historical Analysis | Limited to transformed data | Full historical raw data available |
| Maintenance Complexity | Pipeline changes require rebuilds | Transformation logic easily modified |
When to Use ETL: Best Use Cases
Despite the rise of ELT, ETL remains the right choice for many scenarios. Choose ETL when:
- Strict compliance requirements: Industries like healthcare (HIPAA), finance (SOX, PCI-DSS), and those subject to NIS2 or GDPR often need data scrubbed before storage.
- Legacy system integration: Older on-premises data warehouses may lack the compute power for in-warehouse transformations.
- Complex, stable transformation logic: When transformations are well-defined and rarely change, ETL’s structured approach provides predictability.
- Smaller data volumes: For organizations with manageable data volumes, ETL’s simplicity may outweigh ELT’s scalability benefits.
- Cost-sensitive storage: When storage costs are a primary concern, loading only transformed data keeps expenses predictable.
- Data quality is paramount: When bad data entering your warehouse could have serious business consequences, pre-load validation is essential.
When to Use ELT: Best Use Cases
ELT excels in modern, cloud-native data environments. Choose ELT when:
- Big data and high volumes: ELT handles petabyte-scale data efficiently by leveraging cloud warehouse compute power.
- Cloud-first architecture: Organizations using Snowflake, BigQuery, Databricks, or Redshift can maximize their investment with ELT.
- Real-time and streaming data: When fresh data is critical for decision-making, ELT’s faster loading delivers competitive advantage.
- Evolving analytical requirements: When business questions change frequently, ELT’s flexibility enables rapid adaptation.
- Data science and ML workloads: Data scientists often need raw data access for feature engineering and model development.
- Data lake and lakehouse architectures: ELT aligns with schema-on-read approaches where data structure is defined at query time.
- Diverse data types: When integrating structured, semi-structured (JSON, XML), and unstructured data, ELT provides greater flexibility.
The Rise of ELT: Why Modern Teams Are Making the Switch
The shift from ETL to ELT has accelerated dramatically in recent years. Several factors are driving this transformation:
1. Cloud Data Warehouse Revolution
Modern cloud data warehouses like Snowflake, BigQuery, and Redshift offer virtually unlimited compute and storage that can scale on demand. These platforms are purpose-built for in-warehouse transformations, making the separate ETL transformation layer increasingly unnecessary.
2. The Big Data Explosion
Organizations now generate and consume exponentially more data from an ever-growing number of sources. Traditional ETL transformation bottlenecks simply cannot keep pace with modern data volumes, making ELT’s scalability essential.
3. Demand for Real-Time Insights
Business users expect fresh data for dashboards, alerts, and operational decisions. ELT’s approach of loading first, transforming later, dramatically reduces time-to-insight compared to batch-oriented ETL processes.
4. Rise of the Modern Data Stack
Tools like dbt (data build tool), Fivetran, and Airbyte have created a robust ecosystem specifically designed for ELT workflows. These tools make it easy to build, test, and maintain transformation logic directly in the warehouse.
5. Data Lake and Lakehouse Architectures
The growing adoption of data lakes and lakehouses—which store raw data and apply schema on read—aligns naturally with ELT principles, further accelerating adoption.
6. Self-Service Analytics Demand
Business analysts and data scientists increasingly want direct access to raw data for exploration and discovery. ELT enables self-service analytics without waiting for IT to build new transformation pipelines.
ETL vs ELT: Challenges and Considerations
Both approaches come with challenges that organizations must address for successful implementation.
ETL Challenges
- Pipeline maintenance burden: Changes to source systems often require updating ETL jobs, creating ongoing maintenance overhead.
- Scalability limitations: As data grows, transformation bottlenecks require expensive infrastructure upgrades.
- Longer development cycles: Building and testing ETL pipelines can be time-consuming, slowing time-to-value.
- Limited agility: Responding to new business requirements requires modifying established pipelines.
ELT Challenges
- Data governance complexity: Storing raw data requires robust data quality monitoring and access control frameworks.
- Cost management: Without optimization, storage and compute costs can grow unexpectedly.
- Security considerations: Raw sensitive data in the warehouse demands encryption, masking, and strict access policies.
- Skill requirements: Teams need SQL proficiency and familiarity with modern transformation tools like dbt.
- Risk of data swamps: Without proper cataloging and governance, raw data lakes can become unmanageable.
Hybrid Approach: Combining ETL and ELT
Increasingly, organizations are discovering that the ETL vs ELT choice isn’t binary. A hybrid approach that combines elements of both methodologies often delivers the best results.
When Hybrid Makes Sense
- Mixed source systems: Use ETL for sources requiring heavy pre-processing and ELT for sources that can be loaded raw.
- Compliance requirements: Apply ETL-style transformations to mask sensitive data before loading, while using ELT for non-sensitive datasets.
- Performance optimization: Pre-aggregate or filter very large datasets before loading to reduce warehouse costs, while loading other data raw.
- Legacy integration: Connect older systems via ETL while using ELT for modern cloud applications.
The Peliqan Approach: Best of Both Worlds
At Peliqan, we recognize that modern data teams need flexibility, not rigid adherence to one methodology. Our data pipeline platform combines the strengths of both ETL and ELT:
- ELT-first architecture: We leverage the processing power of modern cloud data warehouses for scalable, flexible transformations.
- Smart pre-processing: For SaaS data sources, we incorporate ETL-like transformations using Singer pipelines to ensure data quality and standardization where it matters.
- Optimized data landing: Data lands directly into relational data warehouses with appropriate column transformations and incremental loading patterns built in.
- No-code flexibility: Business users can work with data through natural language, while technical teams maintain full control over pipeline logic.
Conclusion: Making the Right ETL vs ELT Decision
The ETL vs ELT decision is one of the most important architectural choices for modern data teams. While ELT has gained significant momentum thanks to cloud data warehouses and the demand for real-time analytics, ETL remains relevant for compliance-heavy industries and organizations with specific data quality requirements.
The key is to evaluate your organization’s specific needs: data volumes, compliance requirements, analytical use cases, existing infrastructure, and team skills. Many organizations find that a thoughtful hybrid approach delivers the best results.
At Peliqan, we’re committed to providing flexible, efficient data integration solutions that adapt to your unique requirements. Whether you need the structured approach of ETL, the scalability of ELT, or an intelligent combination of both, our platform helps you unlock the full potential of your data.
Ready to optimize your data transformation strategy? Contact Peliqan today to learn how our innovative approach can streamline your data workflows and deliver actionable insights faster.