In today’s data-driven business landscape, organizations are constantly seeking ways to harness the power of their information. One crucial process that enables companies to make sense of their vast data resources is ETL – Extract, Transform, and Load.
This comprehensive guide will explore the ins and outs of ETL, its importance in modern business intelligence, and how it has evolved to meet the changing needs of data-driven organizations.
What is ETL?
ETL, which stands for Extract, Transform, and Load, is a fundamental process in data integration and management. It involves extracting data from various sources, transforming it into a suitable format, and loading it into a target system, typically a data warehouse or data lake.
The ETL process is crucial for businesses that need to consolidate data from multiple sources, clean and standardize it, and make it available for analysis and decision-making. ETL tools and processes form the backbone of many data integration and business intelligence initiatives.
The ETL Process Explained
ETL process involves the systematic extraction of data from various sources, its transformation into a format suitable for analysis, and its subsequent loading into a data warehouse or similar repository. This process is essential for businesses aiming to harness the power of their data for informed decision-making.
- E – Extract: Data is sourced from one or more locations, which can include databases, spreadsheets, text files, or web services.
- T – Transform: The extracted data is then cleaned, normalized, and manipulated to fit the schema of the target database.
- L – Load: Finally, the transformed data is inserted into the target database, where it can be used for reporting and analysis.
Why is ETL Important?
A survey by Dimensional Research found that 98% of companies consider data quality important for their business operations, highlighting the significance of effective ETL processes. ETL plays a crucial role in modern data management and analytics for several reasons:
- Data Integration: ETL enables organizations to combine data from disparate sources into a single, unified view.
- Data Quality: The transformation phase of ETL allows for data cleansing and standardization, improving overall data quality.
- Historical Analysis: By loading data into a centralized repository, ETL facilitates historical analysis and trend identification.
- Decision Support: ETL processes prepare data for business intelligence tools, supporting data-driven decision-making.
- Regulatory Compliance: ETL can help ensure data consistency and accuracy, which is crucial for regulatory reporting and compliance.
Now that we understand the importance of ETL, let’s examine how it specifically benefits business intelligence efforts.
How Does ETL Benefit Business Intelligence?
ETL is a cornerstone of effective business intelligence (BI) strategies. Here’s how ETL contributes to BI success:
- Data Consolidation: ETL brings together data from various sources, providing a comprehensive view of business operations.
- Data Consistency: By applying transformation rules, ETL ensures that data is consistent across the organization.
- Improved Data Accessibility: ETL processes make data readily available for analysis, reporting, and visualization.
- Enhanced Decision-Making: With clean, consolidated data, business leaders can make more informed decisions.
- Scalability: ETL processes can handle large volumes of data, allowing BI systems to scale as data grows.
| ETL Benefit | Impact on Business Intelligence |
|---|---|
| Data Consolidation | 360-degree view of business operations |
| Data Consistency | Reliable reporting and analysis |
| Improved Accessibility | Faster insights and decision-making |
| Enhanced Decision-Making | More accurate and data-driven choices |
| Scalability | Ability to handle growing data volumes |
With a clear understanding of ETL benefits, it’s time to look at how this process has evolved over the years to meet changing business needs.
The Evolution of ETL
According to a report by Gartner, by 2025, 80% of data integration will be performed using modern ETL and ELT techniques, up from 40% in 2020. The Enterprise ETL landscape has undergone significant changes since its inception:
- Traditional ETL: Initially, ETL processes were batch-oriented and ran on-premises, often requiring significant hardware resources.
- Real-time ETL: With the need for more timely insights, real-time or near-real-time ETL processes emerged, enabling faster data updates.
- Cloud-based ETL: The advent of cloud computing has led to the development of cloud-native ETL tools, offering scalability and flexibility.
- ELT (Extract, Load, Transform): Some organizations now prefer to load raw data first and transform it later, leveraging the processing power of modern data warehouses.
- Data Virtualization: This approach allows for real-time data integration without physically moving data, reducing the need for traditional ETL in some cases.
Traditional ETL vs. Cloud ETL vs. ELT
As data integration needs evolve, it’s crucial to understand the differences between traditional ETL, cloud-based ETL, and the emerging ELT approach.
Traditional ETL vs. Cloud ETL
Traditional ETL processes typically run on-premises, characterized by batch processing, significant upfront investment in hardware and software, and complex setup and maintenance requirements. While offering complete control over the infrastructure, traditional ETL can be inflexible and costly to scale.
In contrast, cloud-based ETL leverages cloud computing resources, offering flexible processing models, pay-as-you-go pricing, and automatic scaling. Cloud ETL provides lower upfront costs, easier integration with cloud-based data sources, and improved agility. However, it may raise data security concerns and potential vendor lock-in issues.
Organizations often choose between traditional and cloud ETL based on factors such as existing infrastructure, data volume, budget constraints, and regulatory requirements. Many adopt a hybrid approach, combining elements of both to meet specific needs.
ETL vs. ELT
While ETL (Extract, Transform, Load) has been the standard approach for data integration, ELT (Extract, Load, Transform) has gained popularity, especially with the advent of powerful cloud data warehouses. In ETL, data is transformed before loading into the target system. This approach allows for data cleaning and standardization early in the process but can be time-consuming for large datasets.
ELT, on the other hand, loads raw data directly into the target system before transformation. This approach leverages the processing power of modern data warehouses, allows for more flexible transformations, and can speed up the initial data loading process. However, it may result in higher storage costs and requires careful management to maintain data quality.
The choice between ETL and ELT depends on factors such as the capabilities of the target system, the need for real-time data availability, and the complexity of required transformations. Some organizations use both approaches, selecting the most appropriate method for each specific use case.
As data integration strategies continue to evolve, understanding these different approaches helps organizations make informed decisions about their data pipeline architectures. Whether opting for traditional ETL, cloud ETL, ELT, or a combination, the goal remains the same: to efficiently transform raw data into valuable business insights.
| Aspect | Traditional ETL | Cloud ETL | ELT |
|---|---|---|---|
| Processing Location | On-premises | Cloud | Target system |
| Scalability | Limited by hardware | Highly scalable | Depends on target system |
| Cost Model | High upfront, ongoing maintenance | Pay-as-you-go | Varies, potentially lower |
| Flexibility | Less flexible | Highly flexible | Very flexible for transformations |
| Data Lake Compatibility | Limited | High | High |
| Real-time Capabilities | Limited | Often supported | Depends on implementation |
When choosing between these approaches, consider factors such as:
- Data volume and velocity
- Existing infrastructure and skill set
- Budget constraints
- Regulatory and compliance requirements
- Need for real-time or near-real-time data processing
- Desired level of control over the ETL process
Many organizations are adopting hybrid approaches, combining elements of traditional ETL, cloud ETL, and ELT to meet their specific needs. The choice ultimately depends on the unique requirements of each data integration project. Now that we’ve compared these different approaches, let’s dive deeper into the specifics of how the ETL process works in practice.
The ETL Process in Detail
Understanding the intricacies of the ETL process is crucial for effective implementation. Let’s dive deeper into each stage:
1. Data Extraction
Data extraction is the first step in the ETL process, involving the retrieval of data from various source systems. These sources can include:
- Relational databases (e.g., MySQL, SQL Server)
- NoSQL databases (e.g., MongoDB)
- Flat files (CSV, XML, JSON)
- APIs and web services
- Web scraping
- IoT devices and sensors
Extraction methods:
- Full extraction: Retrieving all data from the source
- Incremental extraction: Retrieving only new or updated data since the last extraction
- Change data capture (CDC): Identifying and capturing changes in the source data
Challenges in data extraction:
- Dealing with diverse data formats and structures
- Managing large volumes of data
- Ensuring data consistency across sources
- Handling network and connectivity issues
2. Data Transformation
Data transformation is often the most complex and resource-intensive part of the ETL process. It involves cleaning, standardizing, and enriching the extracted data to make it suitable for analysis.
Common transformation tasks include:
- Data cleansing (removing duplicates, correcting errors)
- Data type conversions
- Aggregations and calculations
- Joining data from multiple sources
- Applying business rules and logic
- Normalization or denormalization of data structures
- Encoding and decoding of values
- Handling missing or null values
Advanced transformation techniques:
- Machine learning for data enrichment
- Natural language processing for text analysis
- Geo-coding for location data
- Time series analysis and forecasting
- Sentiment analysis for social media data
Key considerations in data transformation:
- Maintaining data lineage and traceability
- Optimizing performance for large-scale transformations
- Ensuring data quality and consistency
- Handling exceptions and errors
- Managing data dependencies
- Implementing data governance policies
3. Data Loading
The final stage of ETL is loading the transformed data into the target system. This is typically a data warehouse, data mart, or data lake. Loading strategies include:
- Full load: Replacing all existing data with new data
- Incremental load: Adding only new or updated data
- Merge load: Combining new data with existing data based on defined rules
Considerations for data loading:
- Performance optimization (e.g., bulk loading, partitioning)
- Data validation and error handling
- Maintaining data consistency and integrity
- Managing dependencies between different data sets
Now that we’ve explored the ETL process in depth, let’s examine the various architectural patterns used in ETL systems to meet different business requirements.
ETL Architecture Patterns
When designing ETL systems, several architecture patterns can be employed based on specific requirements:
- Batch ETL: Traditional approach processing data in scheduled intervals.
- Pros: Efficient for large volumes, less complex
- Cons: Potential for data latency
- Real-time ETL: Processes data as it arrives, providing near-instantaneous updates.
- Pros: Low latency, fresh data for analysis
- Cons: More complex, potentially higher resource requirements
- Lambda Architecture: Combines batch and real-time processing.
- Pros: Balances throughput and latency
- Cons: Increased complexity in maintaining two systems
- Kappa Architecture: Uses a single stream processing engine for both real-time and batch processing.
- Pros: Simplified architecture, reduced maintenance
- Cons: May not be suitable for all use cases
- Micro-batch ETL: Processes data in small, frequent batches.
- Pros: Balance between batch and real-time, easier error recovery
- Cons: Slightly higher latency than true real-time
ETL Tools List
A wide range of ETL tools are available in the market, catering to different needs and skill levels:
Open-source ETL tools
Commercial ETL tools:
Cloud-based ETL services:
ETL frameworks and libraries:
When choosing the best ETL tool, consider factors such as:
- Scalability and performance
- Ease of use and learning curve
- Integration with existing systems
- Cost and licensing model
- Community support and documentation
With an understanding of ETL architectures, it’s crucial to ensure the reliability and accuracy of these systems. Let’s look at how testing and quality assurance play a vital role in ETL implementations.
ETL Testing and Quality Assurance
Ensuring the reliability and accuracy of ETL processes is crucial. Here are key aspects of ETL testing:
- Data Validation Testing: Verify that data is correctly extracted, transformed, and loaded.
- Business Rule Validation: Ensure that business logic is correctly applied during transformations.
- Performance Testing: Assess the ETL processes ability to handle expected data volumes.
- Integration Testing: Confirm that ETL processes work correctly with other systems.
- Regression Testing: Ensure that changes or updates don’t negatively impact existing functionality.
- Error Handling and Recovery Testing: Verify that the ETL process can handle and recover from errors gracefully.
While testing ensures initial quality, ongoing monitoring and maintenance are essential for long-term success. Let’s explore how to keep ETL processes running smoothly over time.
ETL Monitoring and Maintenance
Ongoing monitoring and maintenance are essential for ensuring the continued effectiveness of ETL processes:
- Performance Monitoring: Track key metrics such as processing time, resource utilization, and data volumes.
- Error Logging and Alerting: Implement robust logging and alerting mechanisms to quickly identify and address issues.
- Data Quality Monitoring: Continuously assess the quality of data flowing through the ETL pipeline.
- Version Control: Maintain version control for ETL code, configurations, and documentation.
- Capacity Planning: Regularly assess and plan for future data growth and processing requirements.
- Security Audits: Conduct regular security audits to ensure data protection throughout the ETL process.
With a solid grasp of ETL operations, let’s turn our attention to the best practices that can help organizations maximize the effectiveness of their ETL processes.
ETL Best Practices
To ensure successful ETL implementations, consider the following 15 best practices:
1. Define clear data governance policies:
-
Establish guidelines for data quality, security, and compliance
-
Define data ownership and stewardship roles
-
Implement data classification and handling procedures
2. Implement robust error handling:
- Design ETL processes to gracefully handle exceptions and data inconsistencies
- Implement retry mechanisms for transient failures
- Create detailed error logs for troubleshooting
3. Optimize for performance:
- Use techniques like parallel processing and incremental loading
- Implement data partitioning and indexing strategies
- Optimize database queries and transformations
4. Maintain data lineage:
- Keep track of data transformations to ensure traceability and auditability
- Implement metadata management systems
- Document data flows and transformations
5. Implement proper testing and validation:
- Develop comprehensive test cases covering various scenarios
- Implement automated testing procedures
- Conduct regular data quality assessments
6. Monitor and log ETL processes:
- Set up monitoring and alerting systems
- Implement dashboards for real-time process visibility
- Regularly review and analyze ETL performance metrics
7. Design for scalability:
- Build ETL processes that can handle growing data volumes
- Use cloud-based or distributed processing frameworks
- Implement auto-scaling capabilities where possible
8. Automate where possible:
- Use scheduling and orchestration tools to automate ETL workflows
- Implement CI/CD pipelines for ETL code deployment
- Automate routine maintenance tasks
9. Implement version control:
- Use version control systems to manage ETL code and configurations
- Implement change management procedures
- Maintain a history of changes and rollback capabilities
10. Provide documentation:
- Maintain clear documentation of ETL processes, data models, and business rules
- Create data dictionaries and glossaries
- Document system architecture and dependencies
11. Ensure data security and privacy:
- Implement encryption for data at rest and in transit
- Apply data masking or anonymization techniques for sensitive information
- Adhere to relevant data protection regulations (e.g., GDPR, CCPA)
12. Optimize resource utilization:
- Implement job scheduling to balance workloads
- Use appropriate hardware or cloud resources based on workload requirements
- Monitor and optimize resource consumption
13. Implement data quality checks:
- Define and enforce data quality rules at each stage of the ETL process
- Implement data profiling to identify potential issues
- Set up data quality dashboards for ongoing monitoring
14. Plan for disaster recovery:
- Implement regular backups of ETL configurations and data
- Develop and test disaster recovery procedures
- Consider implementing multi-region or multi-zone architectures for critical ETL processes
15. Foster collaboration between teams:
- Encourage communication between data engineers, analysts, and business users
- Implement collaborative tools for sharing ETL knowledge and best practices
- Conduct regular training and knowledge-sharing sessions
By following these best practices, organizations can build robust, efficient, and scalable ETL processes that deliver reliable data for business intelligence and analytics.
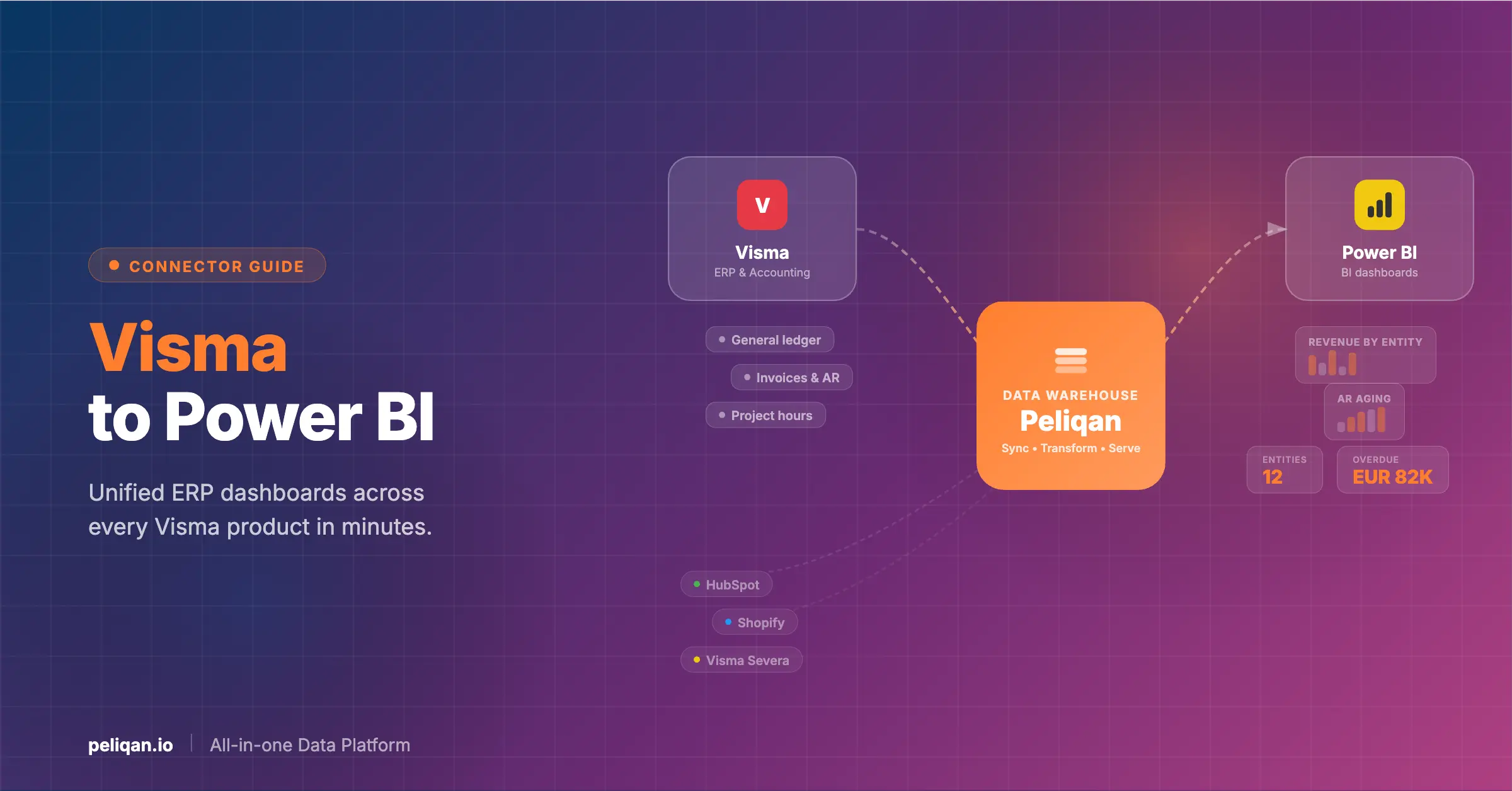
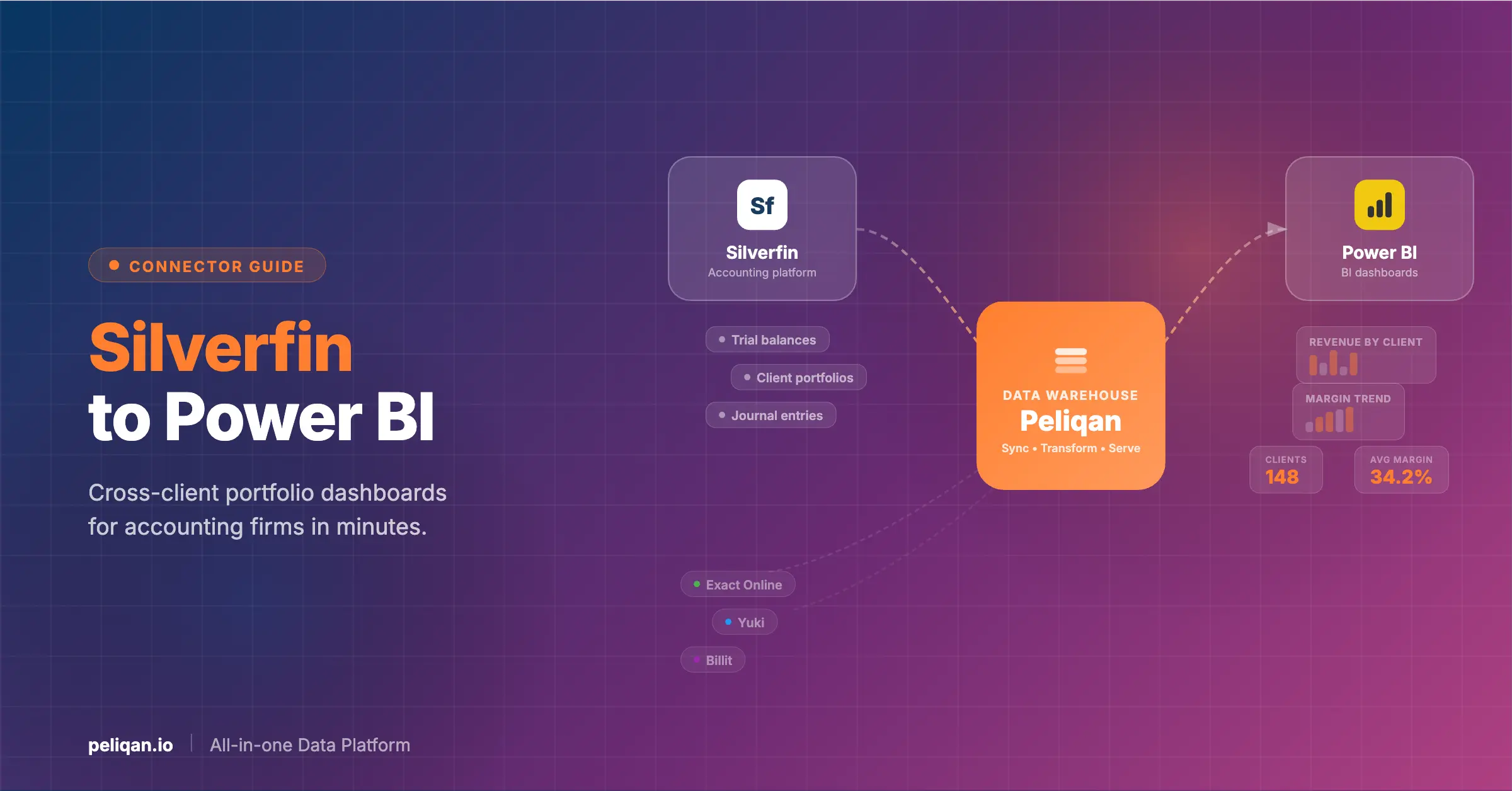
Best Tool for ETL: Peliqan
As we look to the future of ETL, innovative platforms like Peliqan are leading the way in simplifying and automating data integration processes.
Peliqan is an all-in-one platform for all your data needs: connect to all your business applications, ETL your data into a built-in data warehouse or Snowflake & Bigquery, use your favorite BI tool, deploy Metabase or Power BI and other data tools with a single click and implement data activation such as Reverse ETL, publishing API endpoints, sending alerts, distribution of custom personalized reports, live data in Excel etc.
- Comprehensive Data Connectivity: Connect to over 100 SaaS apps, databases, and file sources with ease.
- Built-in Data Warehouse: Use Peliqan’s integrated warehouse or bring your own (Snowflake, BigQuery, etc.).
- Automated ETL Pipelines: Create and maintain ETL processes with minimal effort.
- Flexible Transformation Options: Combine SQL, low-code Python, and AI-assisted transformations.
- Data Activation: Implement reverse ETL, create APIs, and build data apps.
- Business User-Friendly: Explore data using a familiar spreadsheet interface.
- Advanced Features: AI assistance, data lineage tracking, and one-click deployment of popular data tools.
Peliqan’s approach to ETL and data management aligns with the evolving needs of modern businesses, offering a balance of power and simplicity that can accelerate data-driven decision-making.
Conclusion
ETL remains a critical process in the data management landscape, evolving to meet the challenges of modern data environments. From traditional batch processing to real-time, cloud-based solutions, ETL continues to play a vital role in turning raw data into valuable business insights.
As organizations strive to become more data-driven, the importance of efficient and effective ETL processes cannot be overstated. By embracing modern ETL tools and best practices, businesses can unlock the full potential of their data assets, driving innovation and competitive advantage in an increasingly data-centric world.