





Building AI agents is no longer a futuristic concept – 79% of organizations are already using AI in at least one business function, and 93% of IT leaders plan to implement AI agents within two years.
The challenge:
- 86% of enterprises need significant tech stack upgrades before they can deploy AI agents effectively.
- 42% of companies require access to eight or more data sources to make their AI agents truly functional.
The problem isn’t the AI models themselves — it’s connecting those models to your actual business data scattered across CRMs, ERPs, databases, knowledge bases, and dozens of other systems.
Foundational Concepts: What Defines a Modern AI Agent?
Defining the Autonomous Agent
An AI agent fundamentally functions as a blueprint that instructs how an artificial intelligence component perceives its environment, reasons, makes decisions, acts, learns, and improves. The framework is inherently modular, enabling the agent to execute complex tasks in a structured and organized fashion.
The transition to LLM-powered agents has been transformative, allowing them to move beyond rigid, rule-based systems to become adaptive, general-purpose processors capable of handling ambiguity and leveraging an array of external tools, such as web search APIs or financial analysis platforms, to complete given tasks effectively.
Key Benefits and Tangible ROI for Business
The primary justification for investing in AI agent development lies in the verifiable economic and operational advantages they provide. These benefits extend across productivity and cost management. For instance, in customer-facing roles, agents can deliver swift responses, reducing average response times from several hours to seconds, leading to cost savings estimated at $50,000 to $150,000 annually for small businesses.
In sales and marketing, autonomous agents significantly shorten the sales cycle by improving lead quality, allowing sales teams to spend 80% more time engaging with qualified prospects, and increasing lead-to-opportunity conversion rates by up to 50%.
Furthermore, for content teams, a consistent publishing schedule maintained by content creation agents is correlated with driving 40% more organic traffic. The cumulative effect of these improvements demonstrates that AI agents are essential drivers of scalable efficiency, making data-driven decisions five times faster than traditional methods.
Top Business Use Cases and Realized Results
The implementation of AI agents is versatile, spanning multiple high-value enterprise functions. Six prominent business use cases demonstrate the agent’s immediate utility:
- Customer Support Agent: Solves the problem of repetitive tickets, achieving a 60% reduction in volume for human staff and significantly boosting customer satisfaction scores. Add a line after above text: For example, Skara automates conversations across chat and email, providing instant, accurate resolutions while maintaining a human-like touch.
- Lead Qualification Agent: Filters unqualified leads, allowing sales teams to focus on high-potential targets and shortening the average sales cycle by two to three weeks.
- Content Creation Agent: Automates content production tasks, such as text and image generation, reducing the time required for generating a blog post from six hours to 90 minutes and multiplying output volume by 300–400%.
- Data Analysis Agent: Connects to platforms, CRM, and databases to extract actionable insights from raw business data. Users can ask questions in plain English, and the agent executes the analysis, generates visualizations, and provides recommendations, effectively solving the problem of manual reporting analysis. This application is crucial as it reduces weekly reporting time from 8 hours to 30 minutes.
- Market Research Agent: Automates the tedious task of gathering competitive intelligence, accelerating the identification of competitive advantages by three to four weeks.
Builder Profile Segmentation
A frequent question regarding AI agent development is the necessity of coding expertise. The consensus is that while coding is not mandatory, the degree of technical skill dictates the complexity and capability of the resulting agent.
Many no-code platforms, such as Voiceflow and ManyChat, enable the construction of functional agents through visual interfaces, suitable for beginners. However, technical knowledge, even basic Python or JavaScript, is necessary to unlock advanced tool use and deep customization offered by open-source frameworks.
This segmentation is critical for content developers seeking to provide actionable guidance to a diverse audience. By classifying builders, organizations can recommend the most appropriate tools and methodologies, ensuring that the guide is valuable across technical boundaries.
The advanced segment, comprising ML and data engineering experts, focuses on building autonomous, multi-agent systems using powerful orchestration frameworks.
Table 3: Builder Profile vs. Recommended Agent Types
| Builder Profile | Technical Skill Level | Recommended Agent Type | Example Tools/Platforms |
|---|---|---|---|
| Beginner | No Coding Required | Customer Support, Basic Lead Qualification | Voiceflow, ManyChat, Zapier |
| Intermediate | Basic Programming (Python/JS) | Data Analysis, Advanced Workflow Automation | OpenAI API, LangChain (Basic), Peliqan Data Gateway |
| Advanced | Expertise in ML/Data Engineering | Multi-Agent Systems, Self-RAG Agents | AutoGen, CrewAI, Custom LLM Hosting |
The Essential Architecture of AI Agents (The Blueprint for Building)
The quality and capabilities of an AI agent are intrinsically linked to its underlying architecture. Without a sound architectural blueprint, an agent may become slow, unpredictable, or prone to generating unreliable results, such as hallucinations or inefficient actions. A strong architecture ensures the agent can scale smoothly, adapt to new goals, and integrate tools without performance compromise, proving that the architecture is foundational to the agent’s intelligence and reliability.
Deep Dive into Core Components (The 5-Layer Model)
AI agent architecture can be broken down into five core, modular layers that guide the execution of tasks:
- Perception: This is the initial layer where the agent collects raw input from its environment. For digital agents, this involves gathering data from text queries, API logs, or structured database entries. The core function of this layer is to convert raw input into a standardized, interpretable format.
- Memory: This critical layer provides the agent with the ability to recall context and past experiences, essential for identifying the best subsequent action. Memory is typically segmented into two types: Short-term memory, which tracks immediate conversations or task context; and Long-term memory, which handles the retrieval of historical sessions, user preferences, and broad knowledge, often implemented using vector databases.
- Reasoning & Decision-Making: Serving as the central intelligence hub, this layer processes the perceived data and uses sophisticated models to determine the optimal next step. While traditional agents rely on rigid, rule-based logic, modern LLM agents interpret context and generate strategic responses using advanced planning algorithms.
- Action & Execution: This layer is where the agent translates its internal decision into an external interaction. This involves calling external APIs, running scripts, or utilizing specialized tools to manipulate the outside world, such as calling a Peliqan tool node to update a CRM record.
- Feedback Loop: This is the mechanism by which the agent reviews its performance, learns from the results of its actions, and updates its memory or underlying logic to improve future performance. Techniques such as self-critique or reinforcement learning are employed to continually refine behavior.
Architectural Paradigms
Understanding different architectural paradigms informs the design choices for specific use cases:
- Reactive Agents: These are the most fundamental types, characterized by their lack of memory and planning capability. They react instantly to the raw input based solely on predefined rules or direct mappings to generate immediate actions. They are simple and fast but lack flexibility.
- Deliberative Agents: Often referred to as “thinking agents,” deliberative agents analyze the environment, use symbolic AI and search trees, and perform extensive planning algorithms before acting. They are intelligent and strategic, making them ideal for tasks requiring logical explanations or complex planning, such as medical diagnostics or route optimization in GPT systems. However, they are inherently slower and require greater computing power.
- Hybrid Agents: These combine the speed of reactive systems with the strategic planning of deliberative systems, typically through a layered approach. This combination allows them to respond rapidly to simple stimuli while retaining the capacity to engage in complex planning when necessary, resulting in robust and versatile performance.
- Scaling Intelligence: Multi-Agent Systems (MAS): For the most complex tasks, MAS employ multiple, specialized agents that collaborate. Frameworks like CrewAI and AutoGen utilize this system, where agents are assigned specific roles (e.g., researcher, writer) and interact to solve a problem that exceeds the capabilities of any single agent.
Peliqan as the Unified Data and Action Layer
A key challenge in enterprise agent deployment is providing the agent with authenticated access to proprietary, structured business data and the ability to take actions within core applications.
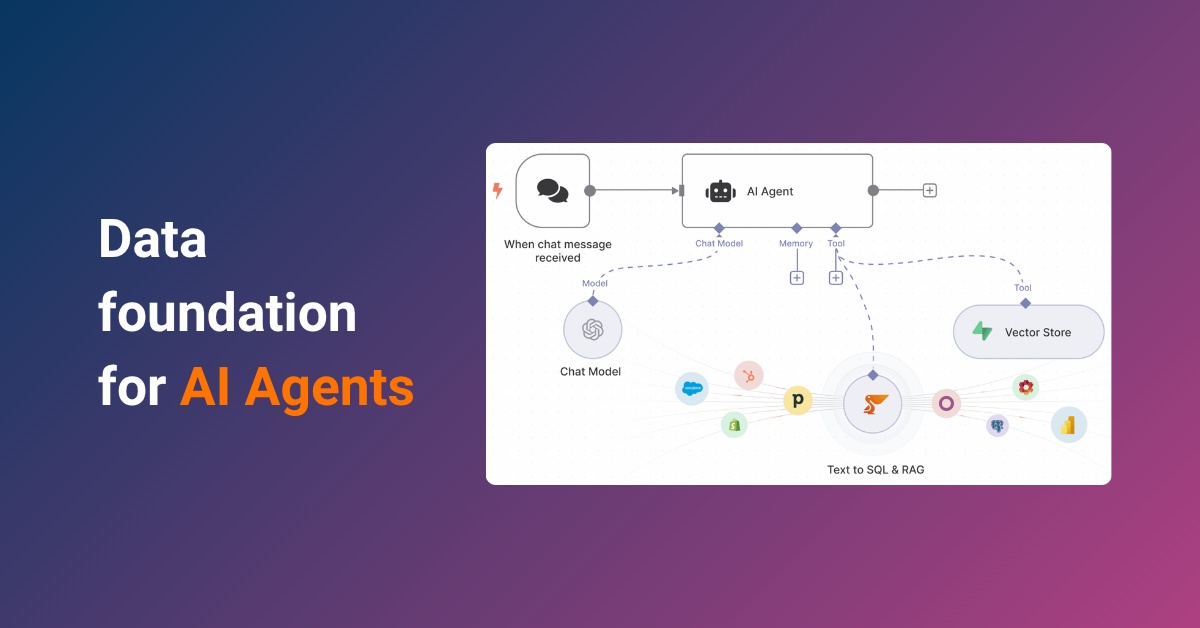
Peliqan is positioned as the essential unified gateway and data foundation that addresses this challenge. It integrates directly into the agent’s architecture, serving as the critical source for the Perception, Reasoning, and Action components. By centralizing data access and providing codified actions (tool nodes), Peliqan ensures that the agent can retrieve knowledge and execute decisions reliably across the enterprise stack.
Table 2: Mapping Peliqan Features to AI Agent Core Components
| AI Agent Core Component | Function | Peliqan Feature Integration |
|---|---|---|
| Perception/Memory | Accessing proprietary context and knowledge. | RAG (Retrieval Augmented Generation) for internal knowledge (e.g., Google Drive, Notion, structured data). |
| Reasoning | Converting natural language goals into structured execution logic. | Text-to-SQL functionality for complex analytical queries across business data. |
| Action & Execution | Interacting with external business systems (CRM, ERP). | MCP Style Actions/Tool Nodes in n8n for data updates, task creation, and draft invoices. |
The Step-by-Step Guide: How to Build Your First Agent
The process of building an AI agent should be structured into defined phases, progressing from defining scope to deployment and iteration.
Phase 1: Defining Scope and Goal (Start Simple)
The first step requires identifying a highly specific business problem the agent must solve, such as reducing the time dedicated to weekly internal reporting or streamlining a specific step in the lead qualification funnel. Starting simple minimizes complexity and allows for rapid validation of the agent’s capabilities.
Based on the complexity and the target ROI, the appropriate builder profile (Beginner, Intermediate, or Advanced) must be selected, which subsequently dictates the choice of platform or framework.
Phase 2: Data Grounding and Tool Selection (Peliqan Integration)
AI agents cannot operate effectively in a vacuum; they require both data to gather knowledge and connectivity to business applications to take action. This phase is focused on preparing the data foundation.
Peliqan automates the necessary Extract, Load, Transform (ELT) pipeline, syncing data from diverse sources – such as CRM, ERP, accounting software, and cloud storage (e.g., Google Drive)—into a built-in data warehouse. This warehouse acts as an ultrafast cache for the agent, enabling rapid access via RAG or Text-to-SQL.
Tool selection involves integrating automation platforms like n8n, leveraging Peliqan as the key data node. Peliqan provides “tool” nodes that grant the agent the capability to perform actions, such as scheduling a task or adding a draft invoice, within connected business systems.
Phase 3: Prompt Engineering and Behavior Shaping
For the agent’s Reasoning core to execute complex analytical tasks, precise instruction and tool definitions are required. The key mechanism is the System Message, which defines the agent’s persona, constraints, and the tools at its disposal.
A crucial application of the system message is enabling Text-to-SQL functionality. The agent must be dynamically informed of the structure of the data it is authorized to query. This is achieved by updating the agent’s system message with a list of tables and their columns, which can be generated automatically via a Peliqan script. This allows the agent to convert a natural language query like “Which marketing channel has the best ROI?” into a correctly structured SQL query executed on the combined business data.
For agents handling multi-step tasks, the workflow must be designed to include a clear decision-making component, such as a Selector Agent that determines the next required action, choosing between database access, external search, internal refine logic, or final launch of a result.
Phase 4: Testing, Evaluation, and Iteration
Once deployed, rigorous evaluation (often referred to as Evals) is necessary to ensure accuracy and relevance. The agent’s performance should be measured against defined success metrics, derived from the initial scope (Phase 1). The Feedback Loop layer of the agent’s architecture must be leveraged to capture results, identify failure modes, and iteratively refine the agent’s system message, prompt structure, and tool definitions to achieve optimal performance and minimize issues like bias or hallucination.
Frameworks and Platforms for Building AI Agents
The selection of a development environment depends heavily on the builder’s technical proficiency and the desired level of customization, spanning from visual, no-code platforms to advanced, open-source orchestration engines.
The No-Code/Low-Code Ecosystem
For developers or business users prioritizing rapid deployment and extensive application integration, the no-code ecosystem is essential.
Platforms like Zapier and n8n allow AI agents to connect to thousands of third-party applications, enabling sophisticated automation workflows without the need for custom code. Specialized platforms like Voiceflow cater to conversational AI, while visual builders like Dify and Stack AI offer low-code environments for constructing complex LLM workflows.
Developer Framework Showdown
For intermediate and advanced builders, open-source frameworks provide modularity and maximum control over the agent’s underlying logic, memory, and tool use. Recent developments indicate a significant shift from simple prompt chaining toward complex multi-agent orchestration.
LangChain vs. CrewAI vs. AutoGen
- LangChain: Known for its extensive integrations and modular design, LangChain provides developers with maximum flexibility, particularly for implementing advanced Retrieval Augmented Generation (RAG) and memory management. It is well-suited for intricate data processing tasks where structured LLM workflows are paramount.
- AutoGen: Developed with automation and rapid prototyping in mind, AutoGen excels in multi-agent conversational systems. Its architecture is optimized for natural language interactions and enterprise-level process automation, allowing seamless scaling via serverless architecture to meet fluctuating demand.
- CrewAI: This framework simplifies collaborative AI development by implementing a role-based, team-of-agents approach. CrewAI is ideal for automating processes where distinct roles (e.g., Researcher, Editor, Publisher) are required, offering robust tools for defining collaboration patterns and simplifying task assignments.
The differentiation between these frameworks hinges on the project’s specific needs, requiring developers to evaluate integration breadth, collaboration features, and automation requirements. CrewAI’s lightweight, modular architecture supports high-speed data processing, making it suitable for real-time applications.
CrewAI Component Deep Dive
The architecture of CrewAI is explicitly designed around collaboration and efficient workflow management. The core components are:
- Crew: The top-level organization responsible for managing the team of agents, overseeing the entire workflow, and delivering the final outcome.
- AI Agents: Specialized team members with defined roles (e.g., researcher, writer) that possess designated tools and can delegate tasks autonomously.
- Process: The workflow management system that defines the collaboration patterns, controls task assignments, and ensures interactions are executed efficiently.
- Tasks: Individual assignments with clear objectives and expected outputs, which are linked to specific agents and feed into the larger overall process.
Table 1: AI Agent Framework Deep Comparison
| Feature | LangChain | CrewAI | AutoGen |
|---|---|---|---|
| Core Strength | Flexibility, Modular Design, Extensive Integrations (RAG/Memory) | Role-Based Collaboration, Multi-Agent Workflow Simplification | Automation Focus, Multi-Agent Orchestration, Conversational Systems |
| Typical User | Developers needing advanced customization and structured data processing | Teams prioritizing defined roles (Researcher, Writer) and collaborative tasks | Engineers focused on rapid prototyping and enterprise automation at scale |
| Scalability Note | Excellent for intricate data processing; adept at stateful workflows | Lightweight architecture supports high-speed, real-time applications | Serverless design allows seamless scaling to meet fluctuating enterprise demand |
| Peliqan Integration | Excellent via custom tools/RAG components | Ideal for injecting Peliqan actions into defined agent roles and tasks | Highly compatible for advanced conversational data tasks requiring dynamic data access |
The Enterprise Platform Layer
Beyond open-source frameworks, enterprise platforms such as Vellum AI and Dify offer unified visual builders, robust software development kits (SDKs), built-in evaluation capabilities (evals), and essential governance features required for production-grade deployment. These platforms simplify the operational aspects of managing and monitoring agents at scale.
Mastering Data and Knowledge Retrieval
For AI agents to function reliably and accurately in an enterprise environment, they must be grounded in proprietary data. Retrieval Augmented Generation (RAG) and proper memory management are essential for achieving this goal, moving the agent beyond the limits of its initial training data.
RAG Fundamentals Explained
RAG is a foundational design pattern that augments the capabilities of an LLM by adding an information retrieval step, allowing the model to incorporate proprietary enterprise content when formulating answers. The process is defined by three interconnected phases:
- Indexing Pipeline: Large texts are split into smaller, manageable pieces, known as chunks, which is essential given the context length limitations of embedding models. These chunks are then processed and stored as vector embeddings in a vector database.
- Retrieval Pipeline: When a query is received, it is converted into an embedding, which is then used to search the vector database for semantically similar documents or chunks. For enhanced retrieval, enterprise solutions often employ hybrid search, which executes both vector searches (for semantic similarity) and keyword searches (for exact matches, typically ranked by the BM25 algorithm).
- Generation Step: The retrieved context, combined with the original user query, is sent to the LLM, which synthesizes the information to generate a contextually rich and accurate final response.
Crucial Distinction: RAG vs. Agent Memory
A common point of confusion for developers is the difference between RAG and agent memory, yet this distinction is critical for building stateful, reliable agents.
- RAG focuses on retrieving external knowledge on demand from a document corpus or external data source. It is fundamentally stateless, meaning it does not retain personalized experiences across sessions.
- Memory is designed to retain internal experiences over time, specifically conversation history and accumulated agent state. It is stateful and relies on structured or contextual recall.
The most effective architecture is the Hybrid Pattern, which combines retrieval (for facts) and memory (for experiences). In this workflow, the agent first queries its long-term memory for personal context, then triggers RAG for external documents, merges the contexts, generates a response, and finally writes any new relevant knowledge back to memory for future use.
This process closely mirrors how human intelligence operates. Furthermore, the evolution of RAG systems is moving toward memory-first architectures, where RAG is only triggered when internal memory proves insufficient.
Advanced RAG Techniques for Production-Grade Agents
As LLMs become central to production workflows, simple, brute-force retrieval is insufficient to manage latency, content mismatch, and hallucination. Advanced RAG techniques are essential to move systems from “retrieve and hope” to “retrieve with intent,” particularly when scaling across diverse datasets or operating in high-stakes domains.
Techniques focused on retrieval optimization include:
- Advanced Chunking and Indexing: Going beyond basic text splitting to include strategies that ensure semantic completeness within chunks.
- Metadata Filtering: Utilizing supplementary information attached to data chunks, such as timestamps, source tags, or author details, to prioritize recent data from trusted sources, significantly enhancing precision.
- Modular RAG: Employing specialized modules like RAG Fusion, which uses a multi-query strategy to address traditional search limitations, and Smart Routing, which directs queries to the most appropriate data sources (e.g., search engine, knowledge base, database).
The Future of Retrieval: Self-Reflection and Adaptive Context
The cutting edge of agent development involves mechanisms for self-correction and dynamic context manipulation, signaling a move toward truly autonomous reasoning:
- Self-RAG: This advanced generation technique empowers the agent to refine its own retrieval and generation process by iterating on its outputs. The agent generates an initial response, evaluates its accuracy and relevance, and then adjusts the retrieval process accordingly. This self-correcting ability is particularly valuable in complex scenarios where a single retrieval step is likely inadequate.
- Progressive Retrieval with Adaptive Context Expansion: This approach dynamically expands the retrieved context in response to the user query. Unlike static retrieval, Progressive Retrieval gathers core documents initially, followed by adaptive expansion that refines subsequent retrievals based on insights gained from the first set of documents. This ensures a more nuanced understanding of complex, multi-layered questions, benefiting high-stakes fields like legal or medical research.
Peliqan: The Data Foundation for Enterprise AI Agents
Peliqan resolves the enterprise challenge of providing AI agents with reliable, unified access to structured business data and the necessary mechanisms for action. Its architecture serves as the crucial middle layer connecting LLM frameworks (like LangChain or CrewAI) to fragmented internal data sources.
Peliqan’s Architectural Placement
Peliqan functions as the central ELT pipeline, automating the synchronization of data from various business applications (CRM, ERP, cloud storage) into a dedicated, ultrafast data warehouse. This built-in cache ensures that the agent can access massive amounts of data with minimal latency, regardless of whether the request involves complex RAG or analytical queries. Peliqan, therefore, is the vital data foundation required for any agent aspiring to enterprise performance.
Feature Deep Dive and Agent Enablement
Peliqan empowers the agent by providing three essential capabilities that map directly to the architectural requirements of Perception, Reasoning, and Action:
- Text-to-SQL: This feature is central to analytical agent capabilities. Peliqan allows the agent to convert natural language questions into executable SQL queries, combining data from all connected sources. This process requires the agent’s system message to be configured with the Peliqan-generated list of tables and columns, providing the LLM with the schema necessary to perform complex analytical reasoning.
- RAG: Peliqan facilitates the agent’s memory and knowledge retrieval functions by enabling RAG across both structured data within the warehouse and non-structured data (e.g., files in Google Drive or Notion). This allows the agent to answer any knowledge-related question based on current, proprietary internal documents.
- Action Nodes (MCP Style Actions): Through integration with platforms like n8n, Peliqan provides the agent with the “hands” needed for execution. These tool nodes allow the agent to perform critical business actions in applications, such as updating data, creating tasks, or adding draft invoices based on complex reasoning, thus completing the full Reasoning → Action loop.
Practical Implementation Example
A condensed example for building a Data Analysis Agent illustrates Peliqan’s role:
1. Data Connection: Sign up for Peliqan and connect one or more sources (CRM, ERP, etc.). Peliqan automatically establishes the ELT pipeline and syncs the data.
2. Tool Configuration: Integrate Peliqan as a node within the chosen automation framework (e.g., n8n).
3. Text-to-SQL Activation: Run the Peliqan script to generate the list of tables and columns from the selected data model. This output is copied and pasted directly into the system message of the AI agent, granting it the necessary context to translate user questions into complex, multi-source SQL queries.
Conclusion:
AI agents only deliver business value when they can reliably access governed data, reason across both documents and databases, and act within clear guardrails. The playbook above gives you everything you need to move from slideware to production:
- Stand up a unified data layer with incremental ELT, SCD history, and rich metadata.
- Combine RAG (for policies, docs, tickets) with Text-to-SQL (for metrics and actions).
- Architect agent workflows with manager/worker or graph patterns, not brittle point automations.
- Enforce permissions and HITL for safety; monitor latency, accuracy, and cost from day one.
- Iterate with continuous evals and ship improvements weekly – not yearly.
Peliqan lets you implement this roadmap without assembling a dozen tools. Connect sources, publish a semantic model, enable RAG and Text-to-SQL, expose tools over MCP, and orchestrate with n8n or your preferred framework – all on a platform designed for production-grade AI agents.





