






Beware, for this is a geeky blog article ! We’ll talk about the different types of workflows found in various data pipeline tools and in the modern data stack. Why ? Seeing the differences will help you understand when to use what type of tool.
Workflows or graphs are a visual representation of a set of “tasks” or “steps” that need to be executed to get some work done. Workflows are used in BPM solutions, in iPaaS platforms, in ETL tools and in orchestration tools.
Let’s talk about these different types of applications briefly:
BPM (Business Process Management)
Business Process Management tools are used to model and automate business processes, for example how an incoming invoice from a vendor is approved and paid. Workflows in BPM tools are typically long running because it can take days or weeks to complete the flow, and they often require manual intervention such as a person that can approve an invoice.
Examples: Camunda, Oracle BPM and many others.
iPaaS (Integration Platform as a Service)
iPaaS software (integration Platform as a Service), or in short “integration platforms”, are focussed on automating steps between SaaS business applications, for example making sure that new customers added in a CRM are also added in the accounting system. iPaaS workflows typically run in the background without human intervention and are often short running processes that take seconds, minutes or hours to complete.
Examples: Workato, Make.com (Integromat), Tray, Qlik Application Automation and many others.
ETL (Extract, Transform, Load)
ETL tools focus on building data flows from various sources into a central data warehouse, with the goal of performing analytics on the data using BI tools or ML/AI. Workflows in ETL tools are often referred to as “graphs” and they run in the background without human intervention.
These flows are often a visual representation of data transformations, they abstract away the complexity of for example writing SQL queries and some tools will help with the logical modelling of data. Modelling data is a complex process where raw data gets transformed into golden tables that can be consumed by business teams. One of the many challenges here is how to handle historical data and potentially using immutable data models. Read our other blog article on this topic!
Orchestration
Orchestration tools are used to automate processes between different systems in order to implement an end-to-end process. In the context of this article we’ll talk about orchestration tools for data pipelines.
Examples: Airflow, Dagster and others.
Control plane versus Data plane
Each of the above platforms use workflows but the way how these workflows are executed differs. First of all, we need to make a distinction between tools that operate on the Control plane versus tools that operate on the Data plane.
The Control plane is the level at which tasks are being orchestrated. Within the context of a data pipeline this means for example starting a task that will extract data from a database or a task that will transform data. However, workflows operating on the Control plane do not handle the actual data, they do not “see” the data. Instead they tell a specific system to do something.
The Data plane is the level at which the actual data is being handled.
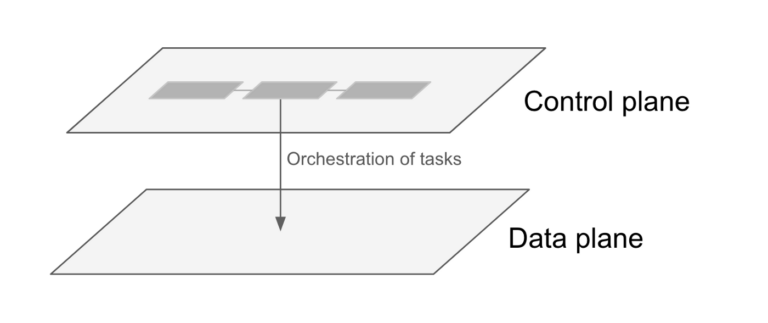
Tasks on the control plane do not handle the actual data, tasks on the data plane do handle the data.
The workflows in orchestration tools — such as Apache Airflow — operate on the Control plane.
The workflows in iPaaS and BPM systems can operate on the control plane, but that’s not always the case, it’s sometimes a mix.
ETL tools operate on the data plane. This means that steps in the workflow define actual handling of data. A good example is Snaplogic, where workflows can define for example transformations on the data that flows through a pipeline.
DAGS (Directed Acyclic Graphs)
In ETL tools, workflows are mostly DAGS, which stands for Directed Acyclic Graphs. A Graph is a type of workflow with nodes and edges that connect the nodes. The nodes are the tasks of the workflow. in a DAG, the workflow is directed which means that it’s clear in which direction the workflow must be executed, that’s nothing special. The most interesting part is that DAGs are acyclic, which means they cannot contain loops.
Why is that ?
Loops are useful, for example if you need to iterate over a set of countries and process data for each country. DAGs are not against loops. But it’s important to understand that DAGs are dependency graphs, which means that tasks will only start when their “parent” tags have been completed. In a DAG you can have multiple tasks that run in parallel and you can wait for all of them to complete before you start the next task.
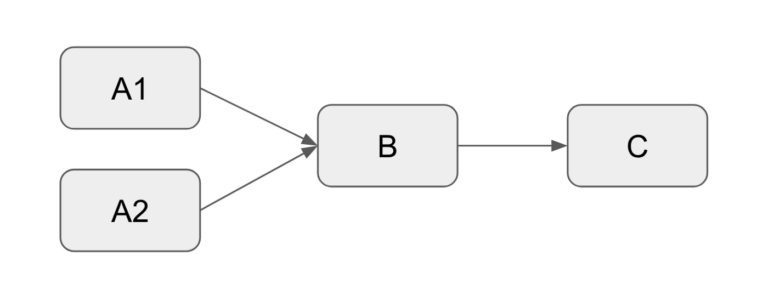
In this dag, task B will start with task A1 and task A2 both have completed. Tasks A1 and A2 can run at the same time, they do not depend on each other.
This concept cannot be married with loops, because you would end up with a deadlock. Here’s an example where task B cannot start because it waits for A (not a problem) and for C (that’s a problem). C cannot start because it depends on B:
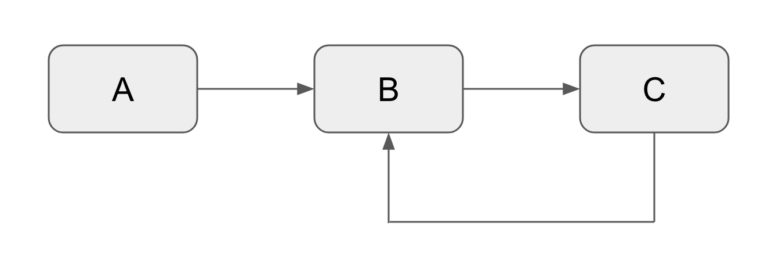
DAGs cannot contain loops, task B would never start because it waits for C to complete while C waits for B to complete.
Does that mean that tools like Airflow — which use DAGS — cannot handle loops ? Of course they can, but the loop or iteration is e.g. implemented inside one individual task but it’s not defined on the visual DAG level.
iPaaS tools such as Tray on the other hand do not use DAGS as their workflows, because loops are such a core concept of the workflows that are being built. The downside of this is that it is harder to implement a scenario where you have to wait for two or more tasks to complete before moving on.
Conclusion
At first sight, all workflows are the same. However, the underlying concept and execution engine can be very different which has an impact on the capabilities of the workflow. It makes sense to have a good understanding of the type of workflow you are using, this will help you to make better implementations and troubleshoot issues efficiently.




